Spring AI
简介
Spring AI 是一个帮助 Java 开发者快速集成 AI 能力的框架。它的设计理念很简单:让 AI 集成变得像使用 Spring Boot 一样简单直接。
虽然受到了 LangChain 和 LlamaIndex 等 Python 项目的启发,但 Spring AI 不是简单的翻译版本。它充分利用了 Spring 生态的优势,为 Java 技术栈量身打造。
解决什么问题? 把企业数据和业务 API 接入 AI 模型,让 AI 真正能理解和处理你的业务场景。
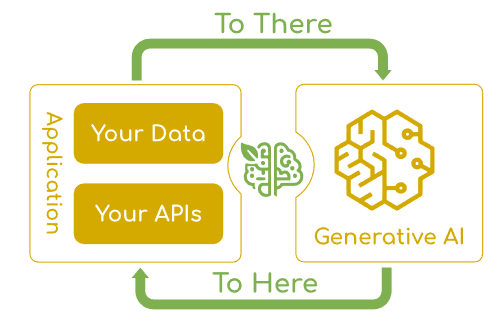
核心概念
1. AI 模型
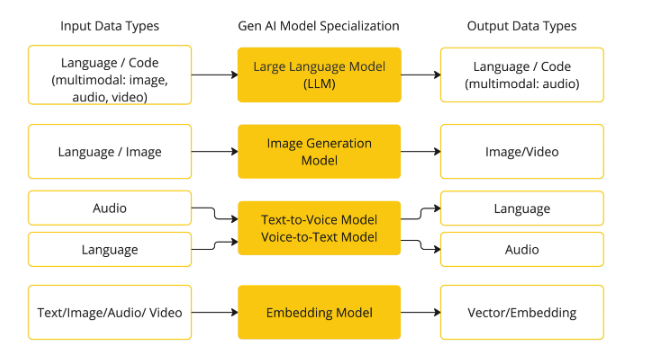
就像数据库有 MySQL、PostgreSQL,AI 模型也有不同类型。按输入输出分类:
- 文本对话:ChatGPT、Claude 这类聊天模型
- 文本生图:Midjourney、Stable Diffusion
- 图像理解:识别图片内容,生成文字描述
- 语音识别:把语音转成文字
- 语音�合成:把文字转成语音
- 文本向量化:把文本转成数字向量(后面会讲用途)
Spring AI 目前支持文本、图像、音频三大类模型。
为什么用预训练模型? GPT 的 "P" 就是 Pre-trained 的意思。预训练模型已经学过海量数据,你不需要懂机器学习,直接调用 API 就能用,就像用数据库一样简单。
2. Prompt(提示词)
Prompt 就是你跟 AI 说的话,但它不只是一句话那么简单。
Prompt 的结构:
- System:设定 AI 的角色和行为规则,比如"你是一个 Java 专家"
- User:用户的实际问题或需求
- Assistant:AI 的历史回复(用于保持上下文连贯)
写好 Prompt 的技巧:
- 把 AI 当人看,用自然语言交流
- 有研究发现,加上"让我们一步步思考"这类引导语,回答质量能提升 30%+
- 多试几次,找到最适合你场景的表达方式
Prompt 模板:
Spring AI 把 Prompt 当成 MVC 中的 View 来处理,支持模板化:
// 模板:Tell me a {adjective} joke about {content}.
Map<String, Object> params = Map.of(
"adjective", "funny",
"content", "programming"
);
这样可以复用 Prompt 逻辑,动态填充参数。
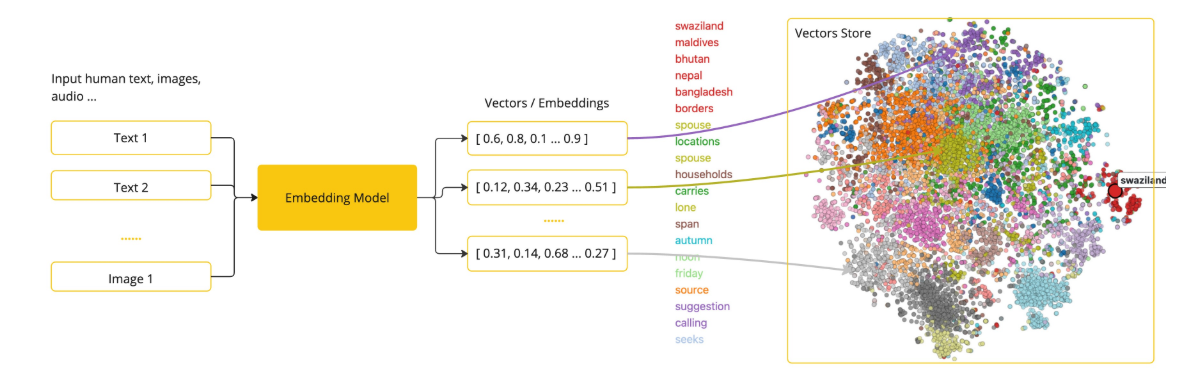
3. Embedding(向量化)
Embedding 把文字、图片、音频转成数字向量。为什么要这么做?因为计算机只认数字。
工作原理:
"Spring Boot 很好用" → [0.2, -0.5, 0.8, ...] (1536维向量)
"SpringBoot 框架不错" → [0.3, -0.4, 0.7, ...]
意思相近的文本,向量也很接近。通过计算向量距离就能判断内容相似度。
为什么有用?
想象你有 10 万篇技术文档,用户问:"Spring 怎么连接数据库?"
传统关键词搜索可能找不到答案(文档里可能用的是"数据源配置"而不是"连接数据库")。但用向量搜索,意思相近的内容都能找到。
典型应用:
- 智能搜索:搜"如何优化查询",能找到"SQL 性能调优"相关内容
- 文档问答:基于企业文档回答问题(RAG 场景)
- 内容推荐:看过 Spring 的人可能对 MyBatis 感兴趣
4. Token(计费单位)
Token 是 AI 模型处理文本的最小单位,也是计费单位。
怎么算 Token?
- 中文:1 个汉字 ≈ 1.5-2 个 token
- 英文:1 个单词 ≈ 1.3 个 token
- 代码:看具体内容,大概和英文差不多
举个例子:一本 10 万字的技术书,大约 15-20 万 token。
为什么要关心 Token?
① 成本问题
GPT-4: 输入 $0.03/1K token, 输出 $0.06/1K token
一次对话 1000 token = 3-6 分钱
如果你做客服机器人,每天上万次对话,成本不容忽视。
② 长度限制
每个模型都有上下文窗口限制:
- GPT-3.5: 4K(约 3000 字)
- GPT-4: 8K-128K 不等
- Claude 3: 最高 200K
超过限制的内容会被截断。所以如果要分析一份 100 页的合同,需要分片处理。
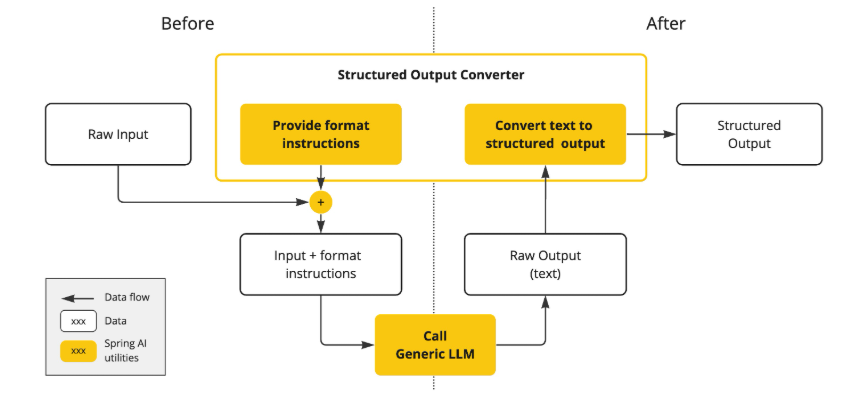
5. 结构化输出
遇到过这种问题吗?
你让 AI 返回 JSON,它给你返回了:
这是一个用户信息:
{
"name": "张三",
"age": 25
}
希望对你有帮助!
这不是合法的 JSON,没法直接 JSON.parse()。
Spring AI 的方案:
public class User {
private String name;
private Integer age;
}
// Spring AI 自动把 AI 输出映射成 Java 对象
User user = chatClient.call(prompt, User.class);
它会在背后优化 Prompt,确保 AI 返回严格的 JSON,然后自动反序列化成你的 POJO。省去了手动解析和容错处理的麻烦。
6. 让 AI 理解你的业务数据
痛点: GPT-4 的训练数据只到 2021 年 9 月,它不知道你公司的业务规则、产品手册、内部文档。怎么办?
有三种方案:
方案一:微调模型(Fine-tuning)
用你的数据重新训练模型。但这个方案:
- 需要大量标注数据和算力
- 成本高(几千到几万美金起步)
- 更新麻烦,数据变了要重新训练
结论: 除非是大厂,普通项目不推荐。
方案二:RAG(检索增强生成)
把相关知识塞进 Prompt 里:
系统:你是客服机器人,这是我们的退货政策:[...政策内容...]
用户:我要退货,多久能到账?
优点:
- 成本低,无需训练模型
- 数据更新方便
- 回答可追溯(能看到引用了哪段文档)
结论: 最常用的方案,性价比最高。
方案三:Function Calling(工具调用)
AI 主动调用你的后端 API 获取数据:
用户:帮我查下订单 1234 的物流
AI:[调用 getOrderInfo(1234)]
AI:您的订单已发货,预计明天送达
优点:
- 数据实时、准确
- 不占用 Prompt 空间
- 能执行操作(不只是查询)
结论: 适合需要调用业务系统的场景。
7. RAG 详解
RAG = Retrieval Augmented Generation,检索增强生成。这是目前 AI 应用最常用的架构。
工作流程
第一步:准备知识库(离线处理)
原始文档(产品手册.pdf)
↓ 分块处理
[第1段] Spring AI 是什么... (500字)
[第2段] 如何配置 OpenAI... (400字)
[第3段] RAG 实现原理... (600字)
↓ 向量化
[0.2, -0.5, ...] → 存入向量数据库
[0.3, 0.1, ...] → 存入向量数据库
关键点:
- 文档要切小块(300-800 字),太大放不进 Prompt,太小上下文不全
- 切块要保持语义完整,不要把一个知识点拆散
- 用表格、代码要特殊处理,保持结构
第二步:用户提问(实时查询)
用户:Spring AI 怎么配置 OpenAI?
↓ 向量化用户问题
↓ 向量数据库检索
找到最相关的 3 段文档
↓ 组装 Prompt
Prompt = """
参考资料:
[第2段内容]
[第5段内容]
用户问题:Spring AI 怎么配置 OpenAI?
请基于参考资料回答,如果资料中没有答案,说不知道。
"""
↓ 发给 AI 模型
AI 返回答案
为什么需要向量数据库?
普通数据库只能精确匹配关键词,向量数据库能理解语义:
- 用户问:"怎么连 MySQL",能找到"数据源配置"相关文档
- 用户问:"接口报 500",能找到"异常处理"相关文档
RAG 的优势
✅ 成本低:不用微调模型,只需要一个向量数据库
✅ 更新快:新增文档直接入库,不用重新训练
✅ 可控性强:能看到 AI 引用了哪些文档,答案可追溯
✅ 准确度高:基于真实文档回答,减少胡编乱造
常见坑
❌ 切块不当:把一个完整的代码示例切断了,AI 理解不全
❌ 检索不准:只找到 1-2 段文档,信息不够,AI 答不好
❌ Prompt 太长:塞了 10 段文档,超出 token 限制
❌ 没有过滤:检索出来的文档不相关,干扰 AI 判断
8. Function Calling 详解
Function Calling 让 AI 能主动调用你的 Java 方法来获取实时数据或执行操作。这是 AI 从"只会聊天"到"能干活"的关键能力。
为什么需要 Function Calling?
RAG 适合处理静态知识,但有些场景必须要实时数据:
- 查询订单状态、库存数量
- 获取天气、股票实时信息
- 执行下单、预约等操作
- 调用计算器、汇率转换等工具
工作原理
用户:帮我查一下北京今天天气
↓
AI 判断:需要调用 getWeather(city) 函数
↓
AI 返回:{"function":"getWeather", "params":{"city":"北京"}}
↓
你的代码执行:getWeather("北京") → "晴天 25°C"
↓
AI 收到结果后生成回复:北京今天晴天,气温 25°C
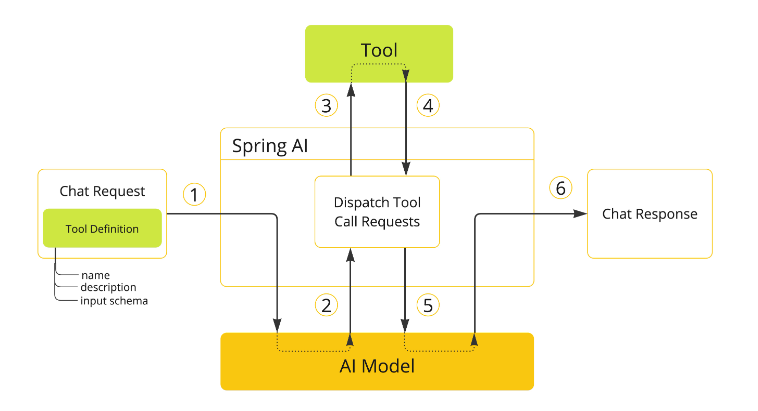
Spring AI 实现示例
1. 定义工具函数
@Component
public class WeatherService {
@Tool(description = "获取指定城市的天气信息")
public String getWeather(
@Param(description = "城市名称") String city
) {
// 实际应该调用天气 API
return "晴天,温度 25°C";
}
@Tool(description = "查询订单物流信息")
public OrderInfo getOrderStatus(
@Param(description = "订单号") String orderId
) {
// 查数据库
return orderRepository.findById(orderId);
}
}
2. 注册到 ChatClient
@Service
public class AIChatService {
@Autowired
private WeatherService weatherService;
public String chat(String userMessage) {
return ChatClient.builder(chatModel)
.defaultTools(weatherService) // 注册工具
.build()
.prompt(userMessage)
.call()
.content();
}
}
3. 实际对话
用户:帮我查下订单 O12345 的物流
AI 内部流程:
1. 判断需要调用 getOrderStatus
2. 调用你的方法:getOrderStatus("O12345")
3. 收到返回:{status: "已发货", logistics: "顺丰 SF123456"}
4. 生成回复
AI 回复:您的订单 O12345 已发货,快递单号是 SF123456(顺丰快递)
多轮调用
AI 可以连续调用多个函数:
用户:我在北京,帮我推荐附近的餐厅,最好是晴天能坐室外的
AI 执行流程:
1. 调用 getWeather("北京") → "晴天"
2. 调用 searchRestaurants(city="北京", hasOutdoorSeating=true)
3. 综合结果生成推荐
与 RAG 的对比
| 维度 | RAG | Function Calling |
|---|---|---|
| 数据类型 | 静态文档、知识库 | 实时数据、动态查询 |
| 更新频率 | 定期更新 | 每次都是最新 |
| 适用场景 | 技术文档问答、FAQ | 订单查询、天气查询 |
| 成本 | 向量化 + 存储 | API 调用成本 |
| 可操作性 | 只读 | 可读可写 |
| Token 占用 | 塞进 Prompt(占用多) | 只传结果(占用少) |
实战场景
场景 1:智能客服
@Tool("查询用户订单列表")
public List<Order> getUserOrders(String userId) { ... }
@Tool("申请退款")
public RefundResult applyRefund(String orderId, String reason) { ... }
@Tool("查询退款进度")
public RefundStatus getRefundStatus(String refundId) { ... }
对话示例:
用户:我要退款
AI:请问是哪个订单需要退款?
用户:昨天买的那个
AI:[调用 getUserOrders] 您昨天有 2 个订单...
用户:就是 199 那个
AI:[调用 applyRefund] 好的,已为您提交退款申请...
场景 2:数据分析助手
@Tool("执行 SQL 查询")
public QueryResult executeQuery(String sql) { ... }
@Tool("生成图表")
public ChartData generateChart(String chartType, QueryResult data) { ... }
对话示例:
用户:帮我看下这个月的销售额
AI:[调用 executeQuery("SELECT SUM(amount) FROM orders WHERE ...")]
AI:本月销售额�是 1,234,567 元,比上月增长 15%
用户:给我画个趋势图
AI:[调用 generateChart] 已为您生成趋势图
注意事项
① 权限控制
@Tool("删除用户数据")
public void deleteUser(String userId) {
// 危险操作!需要严格权限校验
if (!hasPermission(currentUser, "DELETE_USER")) {
throw new PermissionDeniedException();
}
// ...
}
② 参数校验
@Tool("转账")
public TransferResult transfer(
@Param("源账户") String fromAccount,
@Param("目标账户") String toAccount,
@Param("金额") BigDecimal amount
) {
// AI 可能传错参数,必须严格校验
if (amount.compareTo(BigDecimal.ZERO) <= 0) {
throw new IllegalArgumentException("金额必须大于0");
}
// ...
}
③ 成本控制
每次调用都会消耗 token:
- AI 分析是否需要调用:消耗 token
- 函数描述和参数传递:消耗 token
- 返回结果��处理:消耗 token
频繁调用会增加成本,要合理设计函数粒度。
④ 错误处理
@Tool("查询库存")
public StockInfo getStock(String productId) {
try {
return stockService.query(productId);
} catch (Exception e) {
// 返回友好的错误信息给 AI
throw new ToolExecutionException("库存查询失败:" + e.getMessage());
}
}
最佳实践
1. 函数描述要清晰
// ❌ 不好
@Tool("查询")
public Result query(String id) { ... }
// ✅ 好
@Tool("根据订单号查询订单详情,包含商品、物流、支付状态等信息")
public OrderDetail getOrderById(
@Param("订单号,格式为 O + 8位数字") String orderId
) { ... }
2. 返回结构化数据
// ❌ 不好 - 返回字符串
return "订单号:123,状态:已发货,快递:顺丰";
// ✅ 好 - 返回对象
return new OrderInfo(orderId, "已发货", "顺丰", "SF123456");
3. 合理的函数粒度
// ❌ 太细 - AI 要调用多次
getUserName(userId)
getUserAge(userId)
getUserEmail(userId)
// ✅ 合适 - 一次调用获取完整信息
getUserProfile(userId) // 返回 name, age, email 等
RAG + Function Calling 组合
实际项目中,两者经常配合使用:
// RAG 负责静态知识
向量数据库:产品使用文档、FAQ、政策说明
// Function Calling 负责动态数据
@Tool getOrderStatus() // 查订单
@Tool getUserInfo() // 查用户
@Tool submitRefund() // 提交退款
对话示例:
用户:我的订单什么时候能到?你们的配送时效是多久?
AI 执行:
1. [RAG] 从文档检索配送时效政策:"标准配送 3-5 天"
2. [Function] 调用 getOrderStatus 查实时物流:"已发货,预计明天送达"
3. 综合回答:
"根据我们的配送政策,标准配送时效是 3-5 天。
您的订单已发货,快递单号 SF123,预计明天就能送达。"
这样既保证了知识的准确性(RAG),又提供了实时数据(Function Calling),用户体验最佳。