了解LLM大语言模型
大语言模型基础定义
LLM 全称 Large Language Model ,即大语言模型,是一种用大量数据训练的深度学习模型,给模型一些输入,它可以预测并返回相应的输出。
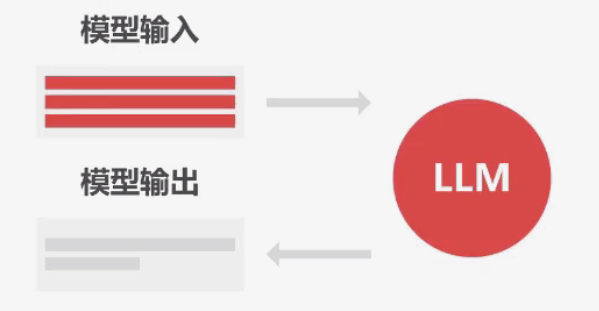
和以往的 NLP 自然语言模型有差异的是, LLM 的训练数据和参数量都非常大,所以 LLM 能完成通用性任务,不需要针对某个领域单独训练。
在大训练数据量+大参数的基础下,大模型能够流畅地完成通用型的任务,而不是像 NLP 自然语言模型一样,针对某个特定领域时需要单独的数据训练才可以实现。
大语言模型完成通用任务
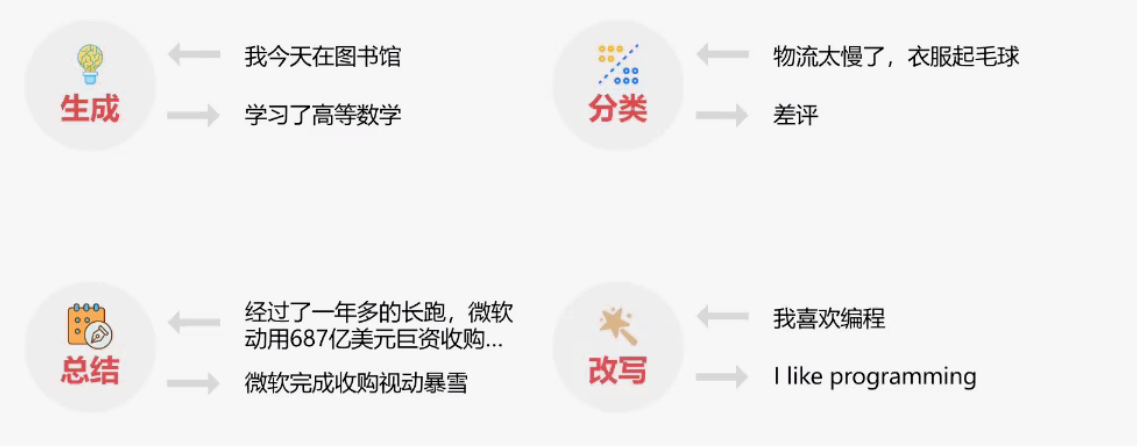
- 生成任务:基于特定的输入(例如关键词、短语或描述性的语句)生成全新的内容或想法。这可能包括写作(例如,文章、短篇故事或诗歌)、艺术品生成、音乐创作等。
- 分类任务:涉及确定给定输入属于哪个类别或群组。大语言模型可以从输入信息中抽取特征,并将其分类到适当的类别。包括情感分析(把文本分为积极,消极,或中性)、图像分类(识别图像中的对象或景色)、语言识别(识别特定的语言类型或方言)等。
- 总结任务:从大量的信息中抽取关键点并生成一个简洁的总结。包括文章摘要(把长篇文章精简为几句关键信息)、会议记录总结(将长时间的会议记录转化为主要讨论点)等。大语言模型能够理解和提炼信息,提供简明、准确的总结。
- 改写任务:指将信息或内容在保持原意的情况下重新表述。包括文本改写(例如,将复杂的语句转化为易懂的语言)、语义等价句生成(例如,用一种新方式表达同一思想)、语言翻译等。大语言模型能够理解语义,从而在改写时保持原始信息的准确性与合理性。
- 参数量大一般指的是 7b 到 100b+,即 70亿 到 100亿 + 参数。
- 参数其实就是一个浮点数(2字节或4字节),比如 3.1415,而在计算机内,使用 2 字节或者 4 字节来存储浮点数类型的数据,70 亿个参数的大小也仅仅为 28G。
大语言模型中的 Token、词表与预测
在大语言模型中,计算长度的依据并不是字符,而是 Token,Token 其实就是文本片段,可以是字、词、甚至是半个字或者三分之一个字。
比如 GPT3.5 上下文长度是 16K,这里的16K 就是 16 * 1024 个 token。
- 对于一个仅支持英语的模型,它的词表可以只有 a-z 26 个字母,加上逗号句号空格等标点符号,Token 数可以非常少。
- 汉字字词更多,语义更加复杂多样,所以包含的 Token 数会更多,很多语言模型都支持多语言,包含各种符号、单词、单词片段等,所以往往会有几十万个 Token 甚至更多。
词表,就是这个模型的所有 Token 映射,每个 Token 有其对应的 id,一般从 0 开始,如下:
"vocab": {
# 开头是一些特殊符号
"<unk>": 0,
"<|startoftext|>": 1,
"<|endoftext|>": 2,
"<|Human|>": 3,
"<|Assistant|>": 4,
...
# 这是字节token,如果出现不在词表中的特殊符号会回退到字节表示
"<0x00>": 305,
"<0x01>": 306,
"<0x02>": 307,
"<0x03>": 308,
"<0x04>": 309,
...
# 下面是正常的英文token,有_的表示是单词的开头,没有的是单词中间
"ct": 611,
"▁re": 612,
"ve": 613,
"am": 614,
"▁e": 615,
...
# 有中文token出现
"安徽省": 28560,
"▁aliens": 28561,
"▁imagery": 28562,
"▁squeeze": 28563,
"子和": 28564,
...
}
有些模型不支持中文,或中文支持度较差,这是因为词表中中文的 token 极少。
大预言模型的工作流程
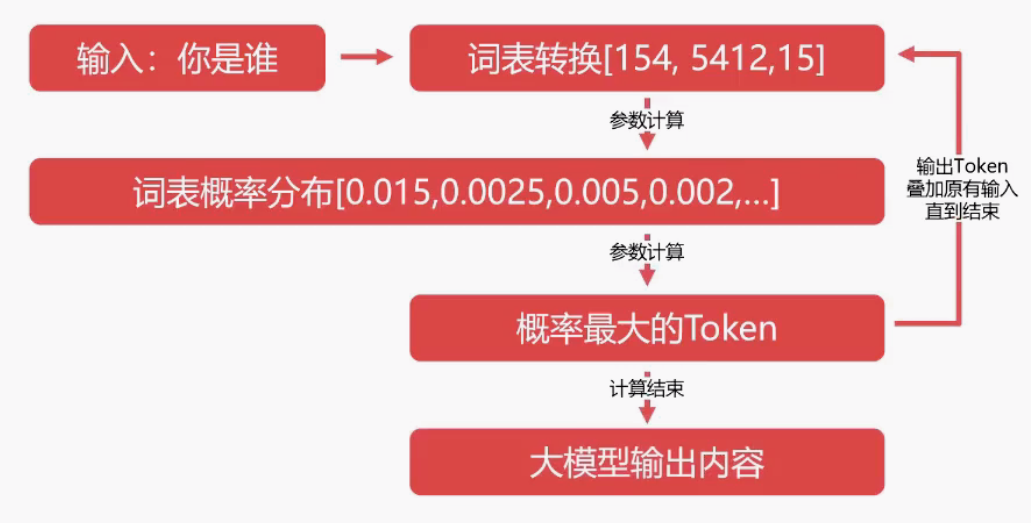
大预言模型预测 Token 的机制
- 如何快速预测下一个 token 是什么呢?一种简单的方法就是基于统计,通过大量数据的统计,找到下一个 token。
- 采集大量文本进行扫描计算,并记录所有片段的输入以及下一个文本出现的次数,得到一张巨大的分布表。
- 将输入的文本对照分布表查询,找到所有 token 的出现次数或改了,找到出现次数最大的 token 即为预测结果。
例如:
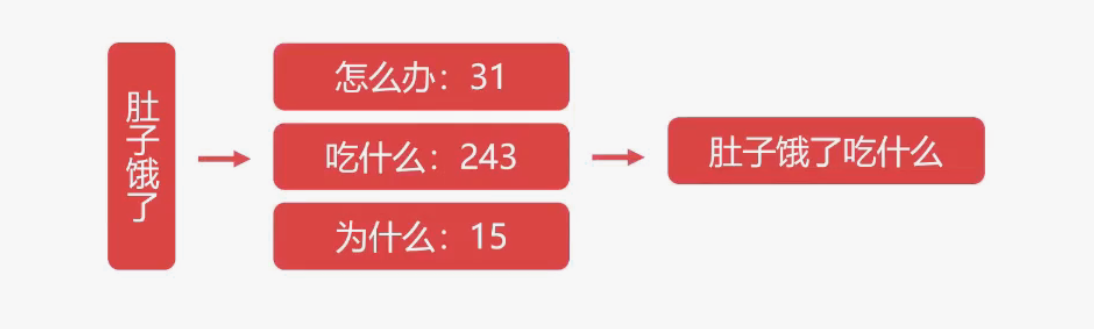
但是基于统计的情况对于没有统计到的片段就无能为力了,比如“唱跳Rap”这个片段并没有在统计中,基于统计的算法会将所有的 Token 出现次数都设置为 0,如下
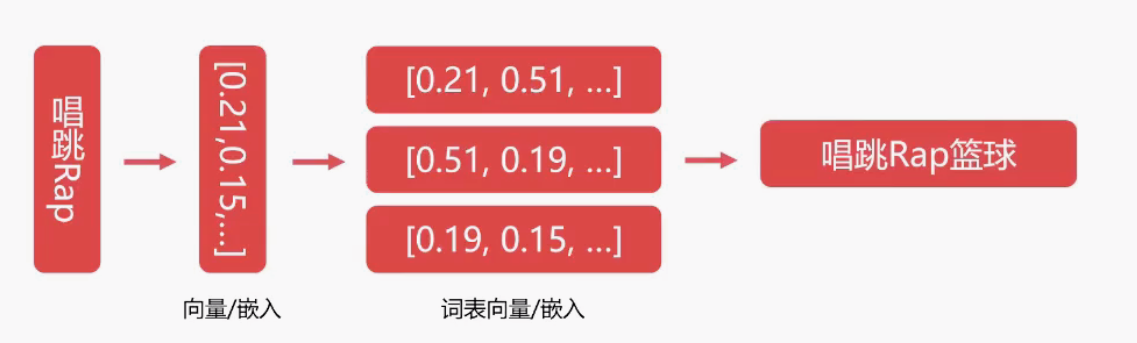
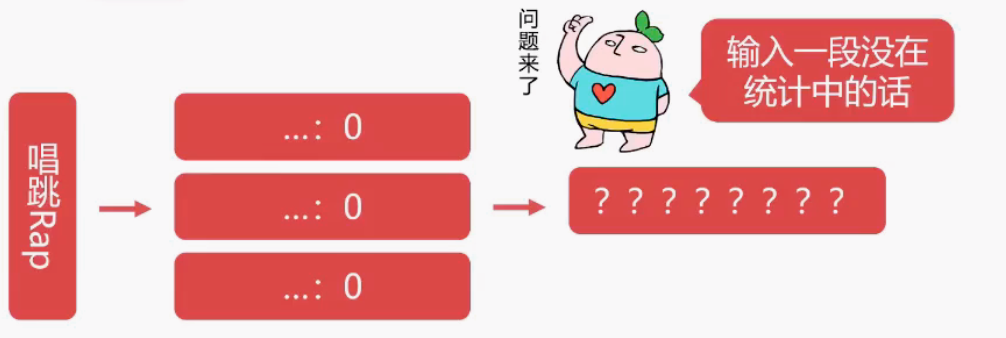 这个时候就可以考虑将输入+词全部转换成向量/文本嵌入,通过向量与向量之间的距离越近,看成概率越大来解决这个问题,在实际的模型中,往往会比这个复杂得多 ,添加向量转换后,整个流程图如下
这个时候就可以考虑将输入+词全部转换成向量/文本嵌入,通过向量与向量之间的距离越近,看成概率越大来解决这个问题,在实际的模型中,往往会比这个复杂得多 ,添加向量转换后,整个流程图如下
模型训练-从随机到智能
- 训练是指将大量文本输入给模型,进而得到 模型参数,目前 LLM 训练一般用到了大量文本,一�般在 2T token 以上。

LLM 在企业中的价值
- 2023 年 GPT-4 发布后,张勇在阿里云峰会上宣布阿里所有产品未来都将迎来升级,并且强调 AI 大模型的出现是一个划时代的里程碑,人类将进入到一个全新的智能化时代,所有的产品都值得用 AI 重做一遍。
- 通用人工智能(AGI)将是 AI 的终极形态,几乎已成为业界共识。类比下来,构建智能体(Agent)则是 AI 工程应用当下的“终极形态”。
- 大模型出现后, AI Agents 衍生出一种新的架构模式,将最重要的 规划/决策部署部分或全部交由LLM完成
智能体指代具有自主性和智能的程序或系统,能够通过感知、规划、决策并执行相关任务。
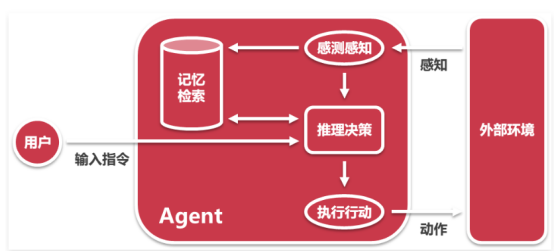
大预言模型的作用在推理、决策这一部分。
Agent/LLM 在企业应用场景应用

1. 基于Agent/LLM的智能客服
- 企业的传统客服存在效率低、培养成本大、工作压力大、提供服务残差不齐等问题,在线客服是企业和客户沟通的桥梁,可以为企业带来更多的商机。
- 利用 LLM + 企业知识库搭建 AI 智能客服,对比传统客服可以实现智能沟通、无间断工作、智能分析、自动分类、跨语言沟通等。
2. 基于Agent/LLM 的数据分析
- 几乎所有企业每天都会产生大量的数据,除了新数据,还有海量的历史沉淀数据,设计:日志、历史代码、订单、会员信息、行业数据等
- 这些数据量庞大、结构差异明显、利用率低,导致企业很难精准获知和及案例各项数据之间的关联。
- 利用 Agent/LLM 参与数据的自动分类、信息提取、数据分析等,建立起各项数据之间的关联。
3. 人工智能即服务-AlaaS
- AI as a Service(AIaaS,AI 即服务)是一项非常新的变革,**将AI视为应用后端服务,让公司发��布一款产品变得及其简单,无需投入昂贵的硬件、专业人才或耗时的开发流程。
- 翻译服务 = 限定的预设 Prompt+LLM规范化输出。
- 自动化运维 = 日志采集 + LLM 推理决策 + 工具包。
现阶段,AI 不会淘汰任何岗位,但会大大减少某些岗位的需求,并创造出大量的高薪/前景好的新岗位。 除此之外,学习 LLM 知识对职业发展还有更多影响,例如: 1.技术领先:掌握更高效的Prompt编写技巧,让LLM更清楚你的需求,更高效完成工作上的任务、疑难杂症等。 2.薪资水平:由于LLM是一个相对新兴的领域,人才短缺,具备相关技能的人才往往能够获得更具竞争力的薪酬。 3.扩充职业前景:随着人工智能的发展和普及,LLM应用的前景非常广阔,不一定所有公司都需要训练LLM,但绝大部分公司都会基于LLM开发应用。
ChatGpt 聊天机器人的使用与局限性
-
ChatGPT 是 OpenAI 基于GPT 架构开发的聊天机器人,可以通过邮箱/Google/Apple账户进行注册登录,推荐使用 Gmail 邮箱注册。
-
GPT-3.5目前可以不限量免费使用,但是 GPT-4 需要付费才可以有限的使用。
-
无法获取实时更新的信息。
-
ChatGPT 底层的 GPT 模型虽然更新的频率飞快,每次更新都会新增训练的内容,但是训练高昂的费用和时间,无法实时将信息投喂给模型进行训练。
-
无法基于企业内部信息进行回答。
-
GPT 模型的训练资料都来源于互联网公开资料集,公司的内部资料并没有再 GPT 的语料库中,所以不会回答关于公司内部信息的问题。或者随意回答。
-
默认无法与外部环境进行交互。
-
默认情况下大模型没有接口与外部进行交互,例如通过爬虫采集特定网站的信息,只有配置后才可以实现。
-
数学能力有限,处理负责问题时,结果往往是错的。大预言模型通过大量参数预测下一个词出现的概率,对于数学问题,大模型采用预测并不一定能计算得准确,特别是复杂的任务。
-
自信地将虚假或者错误的信息呈现给用户(幻觉),如果不核实,很难发现错误,提问:请使用 LangChain+Flash 开发一个简单的机器人聊天接口。
-
大模型语料库如果没有涵盖某些信息,某些场合下,大模型并不会拒绝回答,而是自信地开始胡说八道。
-
处理长上下文,复杂上下文时不连贯,例如向 ChatGPT 提问超过模型能处理的上下文,亦或者对话次数过多时,会出现无法响应的服务器错误。
-
人机对话很强,但不一定是一种很适合的交互方式,例如:通过 GPT + 插件的方式完成剪辑一个视频的前 5 s。