RAG
RAG 的全称是检索增强生成,说起来其实就是两件事:
- 先从资料库里检索相关内容。
- 再基于这些内容来生成答案。
先检索再生成,所以叫做检索增强生成。
RAG 是目前最常见的 AI 问答方案之一,很多企业内的知识助手、智能客服用的都是这项技术。
使用场景
假设你想做一个智能客服,这个智能客服可以回答各种关于公司产品的问题,那应该怎么实现呢,首先这个客服的内部必须要有一个模型,比如 GPT-4o、DeepSeek。
不过光有模型可不够,因为模型不知道公司内部的信息,这个问题好办。
在给模型发送问题的时候,把产品手册一起发给模型就可以解决。
 这确实是一个解决方案。
这确实是一个解决方案。
但是如果产品手册的字数特别多,比如有上百页甚至上千页,就会带来很多问题。
- 模型无法读取所有内容,因为每个模型都只能存储一定量的信息。通常称这个量为上下文窗口大小。如果超出,模型就会读了后面,忘了前面,回答的准确性就会大打折扣
- 模型的推理成本高,输入越多,成�本越高
- 模型推理慢
直接把文档丢给模型是行不通的,那是不是可以考虑只把文档中相关的内容发给模型呢?
大致流程
首先 RAG 会把文档切分成多个片段,当用户提出问题后,就用这个问题在所有片段中寻找相关内容。
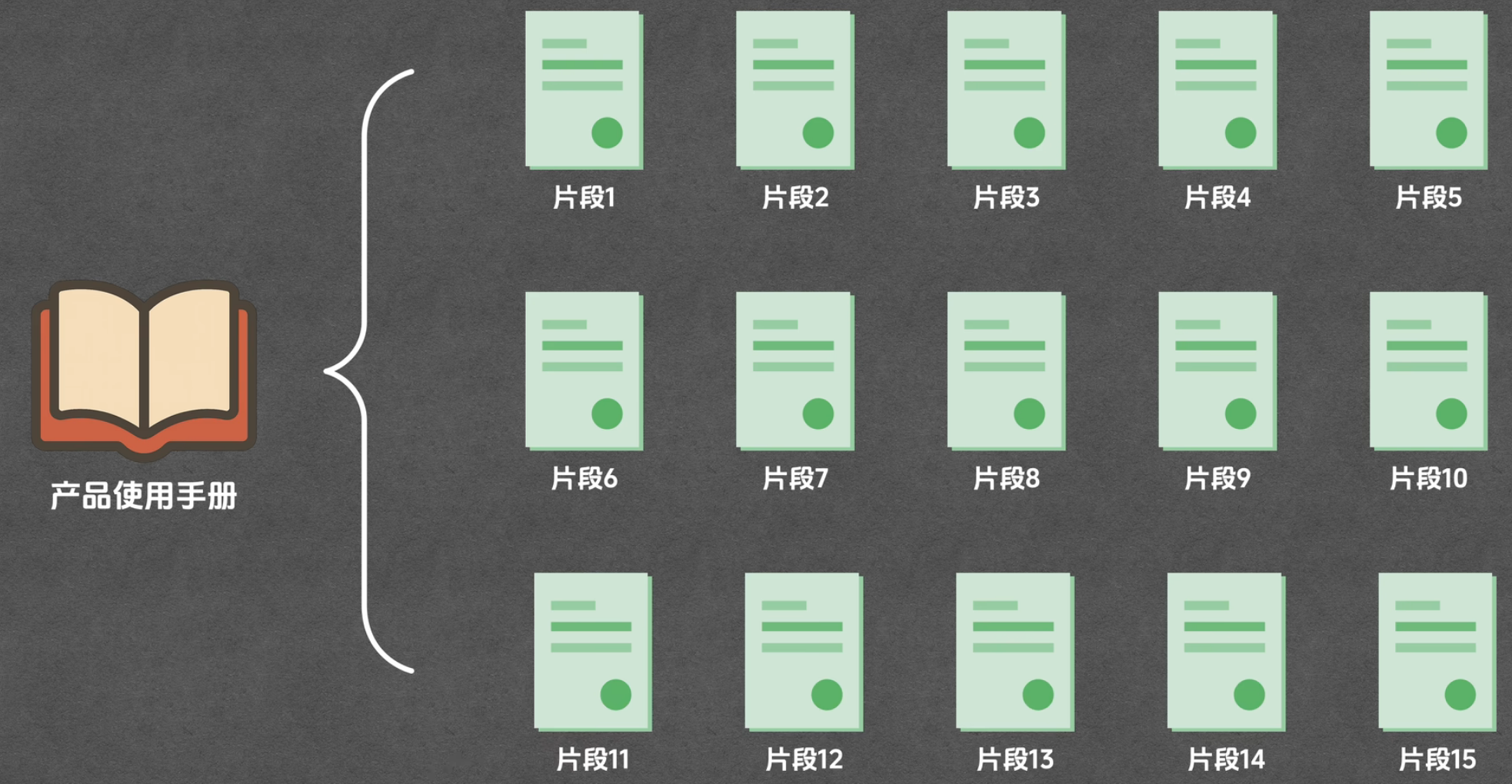 比如在一份上百页的产品手册中,可能只有三个片段与用户的问题相关,那么我们就将这三个片段挑出来,把它们和用户的问题一起发给大模型。
比如在一份上百页的产品手册中,可能只有三个片段与用户的问题相关,那么我们就将这三个片段挑出来,把它们和用户的问题一起发给大模型。
 这样模型就只会感知三个相关的片段,而不是整个文档。之前的问题就会迎刃而解了。
这样模型就只会感知三个相关的片段,而不是整个文档。之前的问题就会迎刃而解了。
上面是一个过度简化的链路,隐藏了很多实现细节,比如:如何分片、如何选择相关的片段。
通常来说 RAG 的整体流程包含两个部分,一个是数据准备部分,这个发生在用户提问前,我们要在这一部分里把相关的文档都给准备好,并完成相应的预处理,它一共是包含分片和索引两个环节。
另一部分是回答部分,这一部分是发生在用户提问之后了,在用户问问题之后,便会触发回答问题的各个环节,分别是召回、重排和生成。
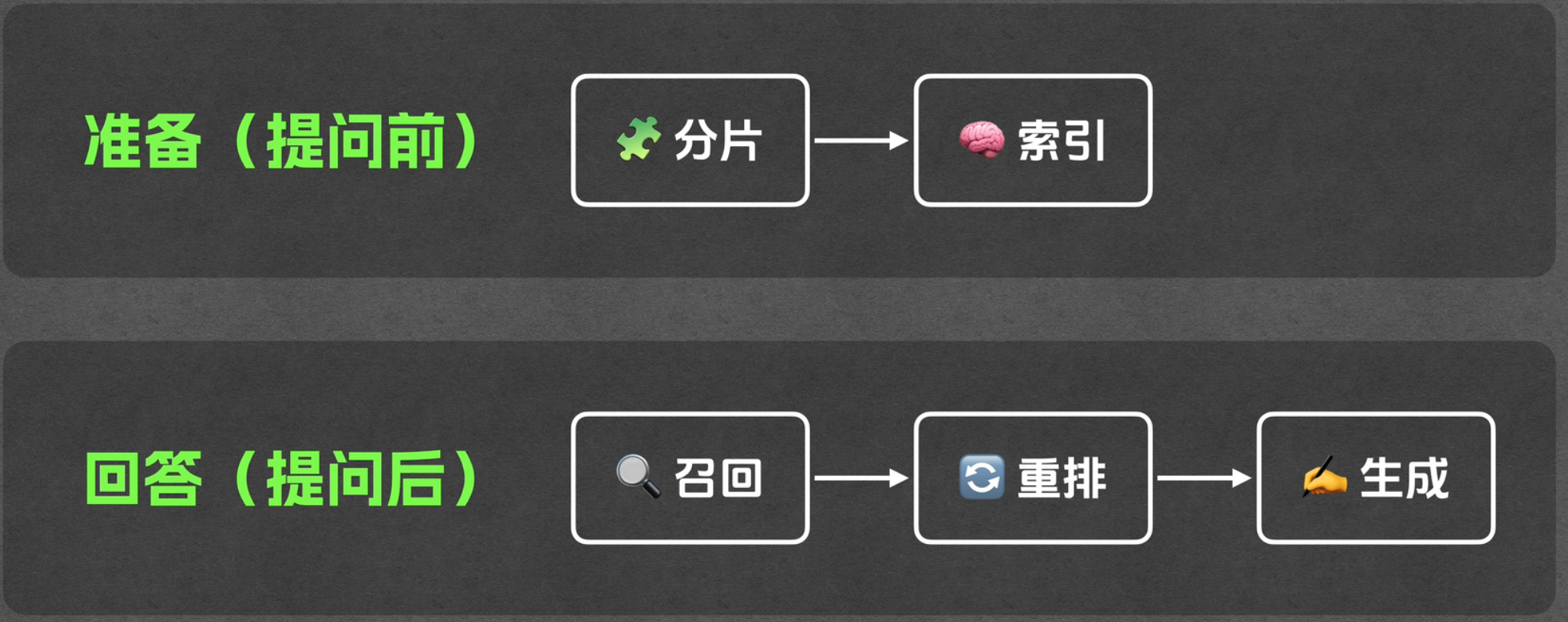
准备(提问前)
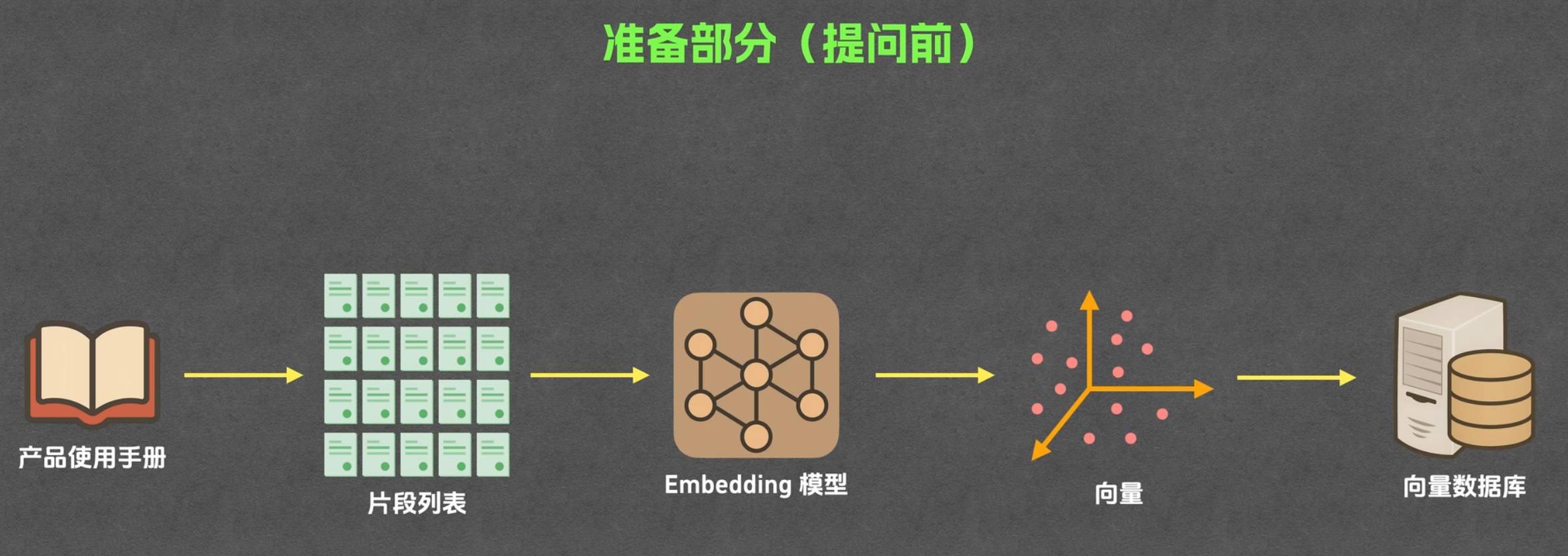
分片
分片,顾名思义,就是把文档切分成多个片段。
分片的方式有很多种,可以按照字数来分,比如说 1000 个字一个片段;按照段落来分,比如说一个段落一个片段;或者按照章节来分;按照页码来分;
 除此之外,还有很多的切分方式,但不管怎么做,最后都需要把一篇文档切分成多份,切好后这个环节就结束了。
除此之外,还有很多的切分方式,但不管怎么做,最后都需要把一篇文档切分成多份,切好后这个环节就结束了。
接着就要进入到下一个环节——索引了
索引
索引过程是下面两个步骤
- 通过 Embedding 将片段文本转换为向量
- 将片段文本和片段向量存储到向量数据库中
向量
向量是数学里面的一个概念,从概念上来讲,它代表一个有大小、有方向的量。
在通常情况下,可以用一个数组来表示它,每个向量都有维度,维度的大小就等于数组中数字的个数

 在 RAG 里面用到的向量维度通常情况都会比较大,比如是几百甚至是几千,维度越大,每个向量所包含的信息也就越丰富。用这些向量做各种工作的可靠性也就越强。
在 RAG 里面用到的向量维度通常情况都会比较大,比如是几百甚至是几千,维度越大,每个向量所包含的信息也就越丰富。用这些向量做各种工作的可靠性也就越强。
Embedding
Embedding 就是把文本转换为向量的一个过程。
含义相近的文本在经历了 Embedding 之后,它们对应的向量也是相近的。
用户提问时,就可以先对用户问题做个 Embedding ,将其转换为向量,然后再根据向量相似度,把与这个问题相关的文本也找出来。最后就可以把这两个相关文本以及用户的问题一起扔给大模型,大模型就可以告诉我们对应的答案了。
Embedding 这个操作是由模型来完成的,不过这个模型可不是我们通常所使用的 GPT-4o、DeepSeek 这样的模型,而是专门的 Embedding 的模型。
如果想知道哪些 Embedding 模型最好用,可以参考 Embedding 模型排行榜
向量数据库
向量数据库就是用来存储和查询向量的数据库,它为存储向量做了很多优化,并且还提供了计算向量相似度等相关的函数,方便我们使用向量,Embedding 后的向量就可以放在向量数据库里面。方便后续查询
要存储的不仅仅是向量,还有原始文本。这样才能通过向量相似度查询出相似的向量之后,把对应的原始文本也抽取出来,发给大模型,让它处理。
最终要使用的还是原始的文本,向量只是一个中间结果。所以一般的向量数据库表格里面至少会有原始文本和向量两列内容。
回答(提问后)
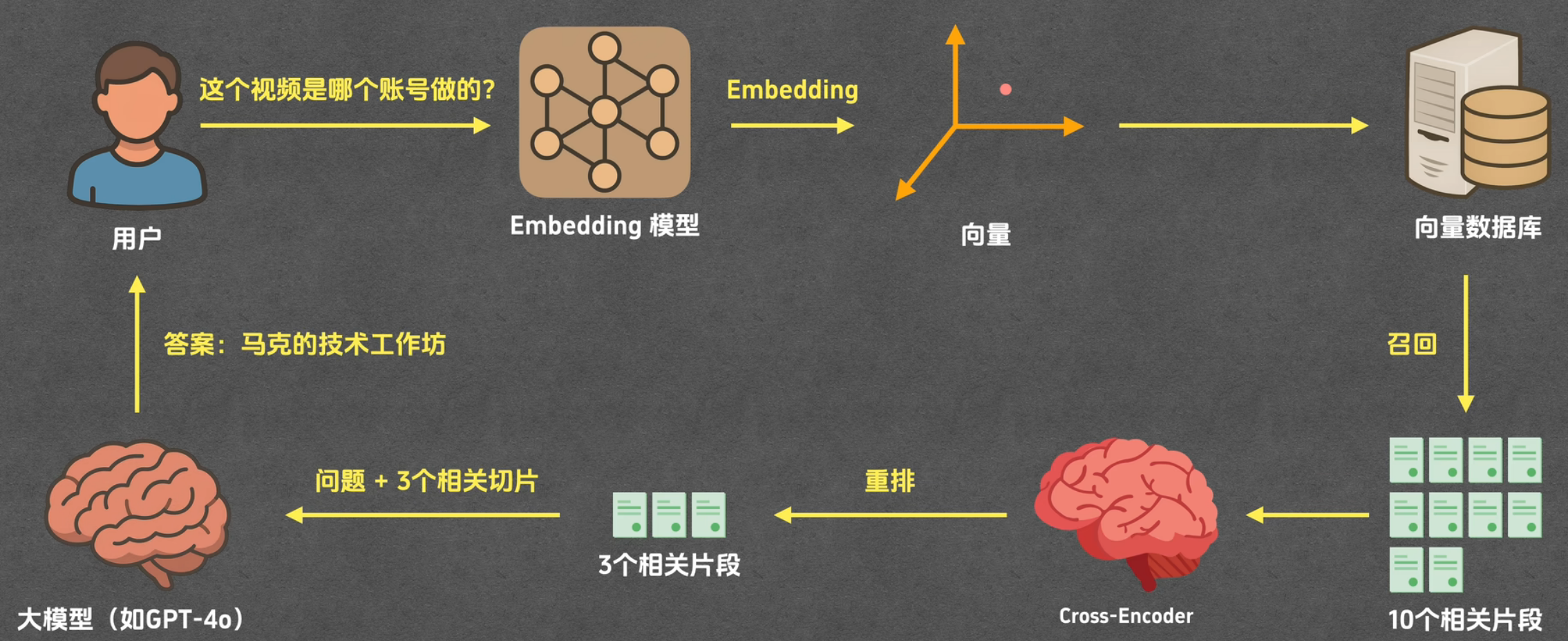
召回
召回就是搜索与用户问题相关片段的过程,这个环节从用户问题开始。
首先,用户问题会发给 Embedding 模型,Embedding 模型会将它转换为向量,然后把它发送给向量数据库,让它查询用户问题最为相关的 10 个片段内容。
召回的结果就是 10 个与用户问题最相关的片段内容。当然 10 这个数字并不��是固定的 ,具体是多少不是很重要,只要不是很多就可以。
如何找出10 个最相关的片段内容,这个时候就要计算向量相似度了。
- 余弦相似度:主要算两个向量之间夹角的 cos 值,根据 cos 值判断夹角的大小,夹角越小,相似度就越高。
- 欧式距离: 计算两个向量之间的距离,距离越小,相似度越高
- 点积
重排
重排全称是重新排序,它做的事情其实跟召回是一样的。
召回是从所有的片段里面挑 10 份与用户问题最相似的,重排是从这些片段中再挑出 3 个最相似的片段。作为重排的结果。
召回和重排阶段使用的文本相似度计算逻辑不一样。
- 召回阶段使用的是向量相似度,适合做初步的筛选。
- 重排阶段一般是使用 cross-encoder 的模型,计算每个片段与用户问题的相似度。相比之下, cross-encoder 的成本会比较高,��耗时也会比较长,准确率高。适合精挑细选。

生成
现在有用户问题,并且有与用户问题相关的三个片段,我们可以把这两部分一起发给大模型,让它根据片段内容来回答用户问题。