语言处理程序
编译过程基本原理
编译程序对高级语言源程序进行编译的过程中,要不断收集、记录和使用源程序中的一些相关符号的类型和特征等信息,并将其存入到符号表中,编译过程如下:
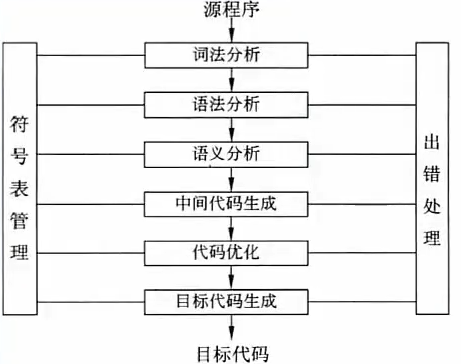
词法分析
是编译过程的第一个阶段。这个阶段的任务是 从左到右一个字符一个字符地读入程序,即对构成源程序的 字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)。
语法分析
是编译过程的一个逻辑阶段。语法分析的任务是 在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等等,语法分析程序判断源程序在结构上是否正确。
语法分析阶段的主要任务是对各条语句的结构进行合法性分析,比如括号不匹配。
语义分析
是编译过程的一个逻辑阶段,语法分析的任务是 对结构上正确的源程序进行上下文有关性质的审查,进行类型审查。如果类型匹配、除法除数不为 0 等。又分为 静态语义错误(在编译阶段能够查找出来)和动态语义错误(只能在运行时发现)。
中间代码生成
中间代码是根据 语义分析产生的,需要 经过优化链接,最终生成可执行的目标代码。引入中间代码的目的是进行与机器无关的代码优化处理。常用的中间代码有 后缀式(逆波兰式)、三元式(三地址码)、四元式和树等形式。需要考虑三个问题(一是 如何生成较短的目标�代码;而是如何充分利用计算机中的寄存器,减少目标代码访问存储单元的次数;三是如何充分利用计算机指令系统的特点,以提高目标代码的质量)。
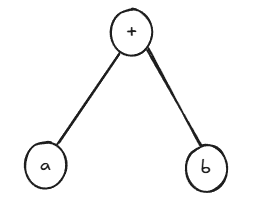
- 前缀表达式:+ab
- 中缀表达式:a+b
- 后缀表达式:ab+
主要掌握上述三种表达式即可,其实就是树的三种遍历,一般 正常的表达式是中序遍历,即中缀表达式,根据其构造出树,再按题目要求写出前缀和后缀式。
简单求法:后缀表达式是从左到右开始,先把表达式加上括号,再依次把运算符加到本层次的括号后面。再去掉所有的括号。
文法
文法用在编译中
字母表、字符串、字符串集合
- 字母表 和字符:字母表是字符的非空有穷集合,字母是字母表 中的元素。例如 = ,a 或 b 是字符。
- 字符串: 中字符组成的有穷序列。例如 a,ab,aaa 都是 上的字符串。
- 字符串的长度:指字符串中字符的个数。如 。
- 空串 : 由零个字符组成的序列,
- 连接:字符串 S 和 T 的连接是指将串 T 接续在串 S 之后,表示为 S·T,连接符号 “·” 可省略。
- : 是指空串 在内的 上所有字符串的集合。例如: ,
- 字符串的方幂:把字符串 自身连接 n 次得到的串,称为字符串 的 n 次方幂,记为 ,,
字符串集合上的运算
设 A,B 代表字母表 上的两个字符串集合。
- 或(合并):
- 积(连接):
- 幂:,并规定
- 正则闭包+:
- 闭包*:,显然
文法定义
文法 G 是一个四元组,可表示为 G=(V,T,P,S),其中:
- V: 非终结符,不是语言组成部分,不是最终结构,可以推导出其他元素。
- T: 终结符:是语言的组成部分,是最终结果,不能再推导其它元素。
- S: 起始符, 是语言的开始符号。
- P: 产生式。用终结符代替非终结符的规则,例如 a->b
乔姆斯基把文法分为 4 种类型,即 0 型、1 型 、2 型和 3 型。
- 0 型文法也称为短语文法,其概念相当于图灵机,任何 0 型语言都是递归可枚举的;反之,递归可枚举的也必定是一个 0 型语言。
- 1 型文法也称为 上下文有关文法,这种文法意味着对非终结符的替换必须考虑上下文,并且一般不允许替换为 串。例如,若 是 1 型文法的产生式, 和 不全为空,则非终结符 A 只有在左边是 ,右边是 的上下文中才能替换成 。
- 2 型文法就是 上下文无关文法,非终结符的替换无需考虑上下文。程序设计语言中大部分语法都是上下文无关文法,当然语义上是相关的,要注意区分语法和语义。
- 3 型文法等价于正规式,因此也称为正规文法或线性文法。
正规式
语言中具有独立含义的最小语法单位是符号(单词),如标识符、无符号常数与界限符等等。词法分析的任务是把构成源程序的字符串转换成单词符号序列。
词法规则可用 3 型文法(正规文法)或正规表达式描述,它产生的集合是语言规定的基本字符集 (字母表) 上字符串的一个子集,称为正规集。正规式和正规集
对于字母表 ,其上的正规式及其表示的正规集可以递归定义如下:
- 是一个正规式,它表示集合 。
- 若 是 上的字符,则 是一个正规式,它所表示的正规集为 。
- 若正规式 r 和 s 分别表示正规集 L(r) 和 L(s),则:
r|s是正规式,表示集合r·s是正规式,表示集合- 是正规式,表示集合
- (r) 是正规式,表示集合
仅通过 有限次使用上述 3 个步骤定义的表达式才是 上的正规式,其中,运算符 “|”,“·”,“*”
分别称为“或”,“连接” 和 “闭包”在正规式的书写中,
连接运算符 “·” 可以胜利,运算的优先级从高到低排列为“*” “·” “|”。
设 ,下表列出了 上的一些正规式和相应的正规集。
| 正规式 | 正规集 |
|---|---|
| ab | 字符串 ab 构成的集合 |
| a|b | 字符串a、b 构成的集合 |
| 由 0 个或多个 a 构成的字符串集合 | |
| 所有字符 a 和 b 构成的串的集合 | |
| 以 a 为首字符的 a、b 字符串的集合 | |
| 以 abb 结尾的 a、b 字符串的集合 |
有限自动机
有限自动机是一种识别装置的抽象概念,它能 准确是被正规集。有限自动机分为确定的有限自动机和不确定的有限自动机两类。
确定的有限自动机 DFA
一个确定的有限自动机是个五元组(S,,f,,Z),其中:
- S 是一个有限集,其每个元素称为一个状态。
- 是一个有穷字母表,其每个元素称为一个输入字符。
- f 是 S x 上的单值部分映像。f(A,a) = Q 表示当前状态为 A、输入为 a 时,将转换到下一状态 Q。称 Q 是 A 的一个后继状态。
- , 是唯一的一个开始状态。
- Z 是非空的终止状态集合, 。
状态转换图示例如下:
不确定的有限自动机 NFA
一个不确定的有限自动机也是一个五元组,它与确定的有限自动机区别如下:
- f 是 上的映像,对于 S 中的一个给定状态及输入符号,返回一个状态的集合。即当前状态的后续状态不一定是唯一的。
- 有向弧上的标记可以是 。
确定的有限自动机和不确定的有限自动机:输入一个字符,看是否能得出唯一的后继,若能,则是确定的,否则若得出多个后继,则是不确定的。
语法分析方法
自上而下语法分析
最左推导、从左至右。给定文法 G 和源程序串 r,从 G 的开始符号 S 触发,通过反复使用产生式对句型中的非终结符进行替换(推导),逐步推导出 r。
递归下降思想:原理是利用函数之间的 递归调用模拟语法树自上而下的构造过程,是一种自上而下的语法分析方法。
自下而上语法分析
最右推导,从右至左。从给定的输入串 r 开始,不断寻找子串与文法 G 中某个产生式 P 的候选式进行匹配,并用 P 的左部代替(归约)之,逐步归约到开始符号 S。
移进-归约思想:设置一个栈,将输入符号逐步移入到栈中,栈顶形成某产生��式的右部时,就用左部代替,称为归约。很明显,这个思想是通过右部来推导出左部,因此是自下而上语法分析的核心思想。