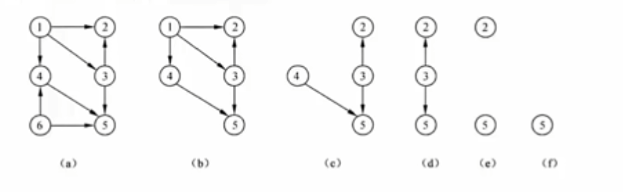
图
基础概念
-
无向图:图的结点之间连接线是 没有箭头的,不分方向
-
有向图�:图的结点之间连接线是箭头,区分 A 到 B,和 B 到 A 是两条线。
-
完全图:无向完全图中,节点两两之间都有连线,n 个节点的连线数为(n-1)+(n-2)+...+1 = n*(n-1)/2; 有向完全图中,节点 两两之间都有互通的两个箭头,n 个节点之间的连线数为 n*(n-1)。
-
度、入度和出度:顶点的度是 关联与该顶点的边的数目。在有向图中,顶点的度为 出度和入度之和。
-
路径:存在一条通路,可以从一个顶点到达另一个顶点。
-
子图:有两个图 G=(V,E)和 G'=(V',E') ,如果 V' 属于 V 且 E' 属于 E,则称 G' 是 G 的子图。
-
连通图和连通分量: 针对无向图,若从顶点 v 到顶点 u 之间是 有路径的,则说明 v 和 u 之间是联通的,若无向图中 任意两个顶点之间都是连通的,则称为联通图。无向图 G 的 极大连通子图称为其连通分量。
-
强连通图和强连通分量:针对 有向图。若有向图 任意两个顶点间度相互存在路径,即存在 v 到 u ,也存在 u 到 v 的路径,则称为强连通图。有向图中的 极大连通子图称为其强连通分量。
-
网:边带权值的图称为网
图的存储
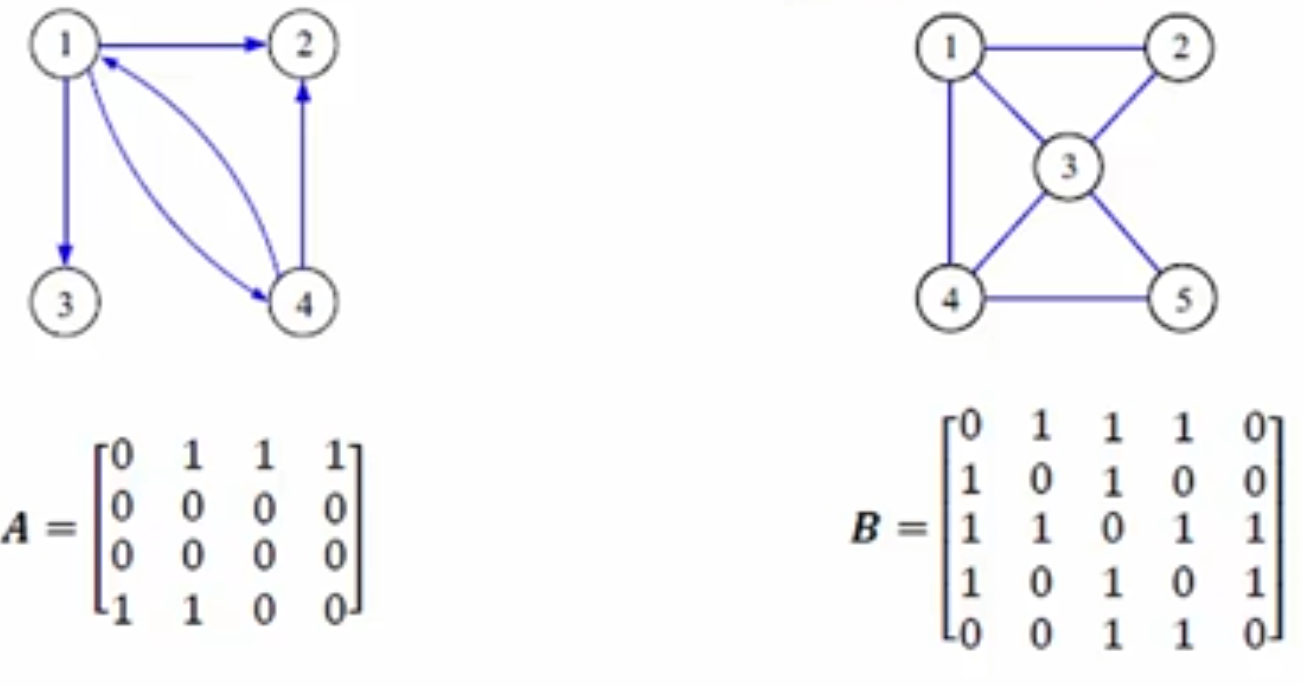
邻接矩阵
假设一个图中有 n 个节点,则使用 n 阶矩阵来存储这个图中各个节点的关系,规则是若节点 i 到 节点 j 有连线,则矩阵 ,否则为 0 ,示例如下图所示:
邻接链表
用到了两个数据结构,先用一个 一维数组将图中所有顶点存储起来,而后,对此一维数组的 每个顶点元素,使用链表挂上其出度到达的节点的编号和权值,示例如下图所示:
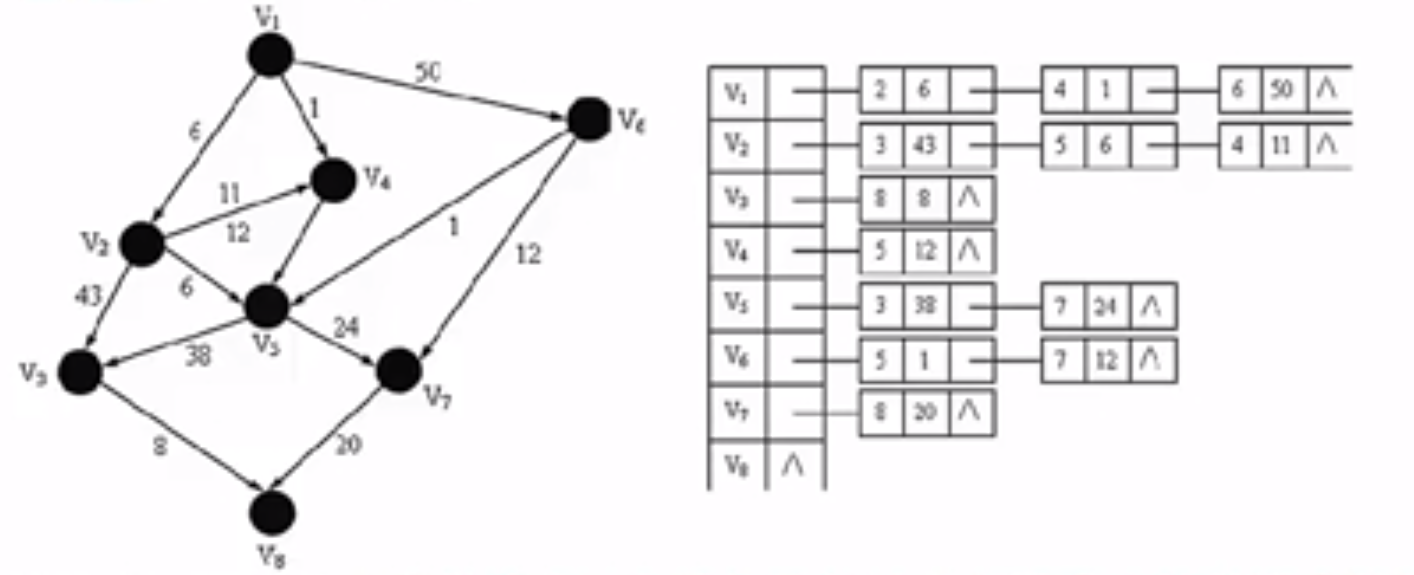
图中的 顶点数决定了一维数组的大小和邻接表中的单链表数目,边数的多少决定了单链表中的节点数,而不影响邻接矩阵的规模,因此采用何种存储方式与有向图、无向图没有区别,要看图的边数和顶点数,完全图适合采用邻接矩阵进行存储。
邻接矩阵的大小跟节点数相关,邻接链表的大小既跟节点相关,也跟边相关,节点的个数决定了一维数组的大小,边的个数决定了单个链表的大小。
图的遍历
图的遍历是指 从图的任意节点出发,沿着某条搜索路径对图中所有节点进行访问且只访问一次,分为以下两种方式:
- 深度优先遍历:从 任一顶点触发,遍历到底,直至返回,再选取任一其他节点出发,重复这个过程直至遍历完整个图。
- 广度优先遍历:先访问完一个顶点的所有邻接顶点,而后再一次啊访问其邻接顶点的所有邻接顶点,类似于 层次遍历。
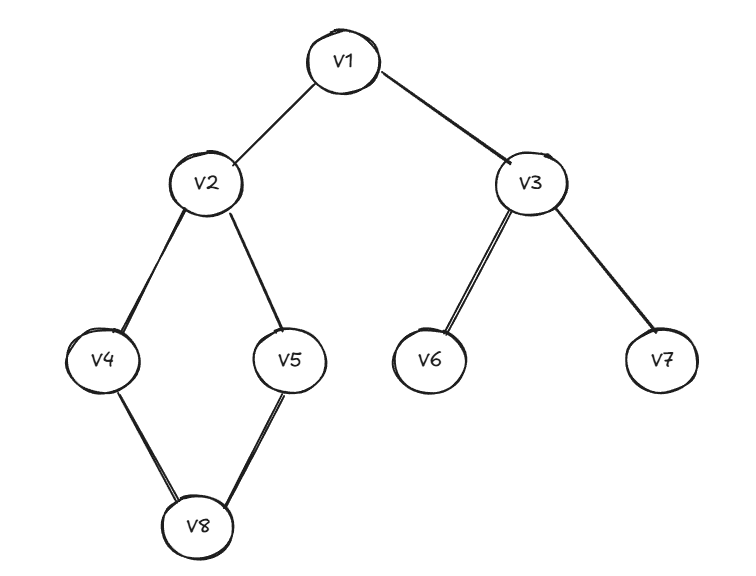
| 遍历方法 | 说明 | 示例 |
|---|---|---|
| 深度优先 | 1. 首先访问出发顶点 V 2. 依次从 V 出发搜索 V 的任意一个邻接点 W 3. 若 W 未访问过,则从该点出发继续深度优先遍历 它类似于树的前序遍历 | V1,V2,V4,,V8,V5,V3,V6,V7 |
| 广度优先 | 1. 首先访问出发顶点 V 2.然后访问与顶点 V 邻接的全部未访问顶点 W、X、Y... 3. 然后再依次访问 W、X、Y... 邻接的未访问的顶点; | V1,V2,V3,V4,V5,V6,V7,V8 |
图的最小生成树
假设有 n 个节点,那么这个图的最小生成树有 n-1 条边(不会形成环路,是树非图),这 n-1 条边应该会将所有顶点都连接成一棵树,并且 这些边的权值之和最小,因此称为最小生成树,共有下列两种算法。
- 普利姆算法:从 任意顶点出发,找出 与其相邻的边权值最小的,此时 此边的另一个顶点自动加入树集合中,而后 再从这个树集合的所有顶点中找出与其邻接的边权值最小的,同样此边的另外一个顶点加入树集合中,依次递归,直至图中所有顶点都加入树集合中,此时此树就是该图的最小生成树。 普利姆算法的时间复杂度是 O(n^2),与图中的边数无关,因此适合于求边稠密的网的最小生成树。
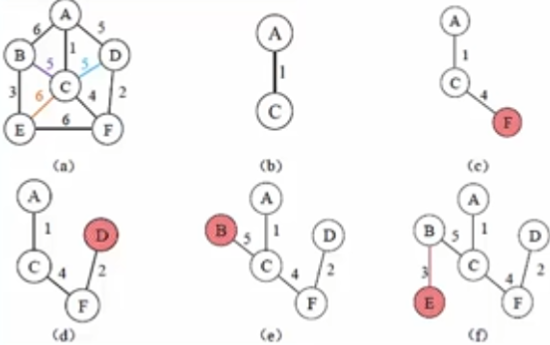
- 克鲁斯卡尔算法(推荐):这个算法是 从边出发的,因为本质是选取权值最小的 n-1 条边,因此,就 将边按权值大小排序,依次选取权值最小的边,直至囊括所有节点,要注意,每次选边都要检查不能形成环路。克鲁斯卡尔算法的 时间复杂度为 O(eloge),因此该算法适合求边稀疏的网的最小生��成树。
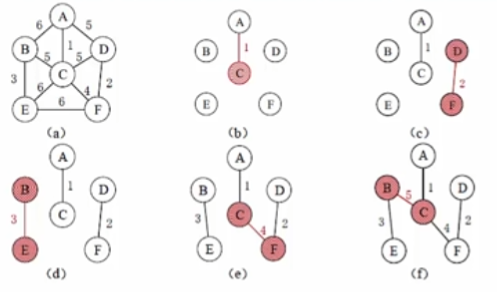
拓扑序列
若 图中一个节点的入度为 0,则应该最先执行此活动,而后删除掉此节点和其关联的有向边,再去找图中其他没有入度的节点,执行活动,依次进行,示例如下图(有点类似进程前驱图原理):