线性结构
线性结构定义
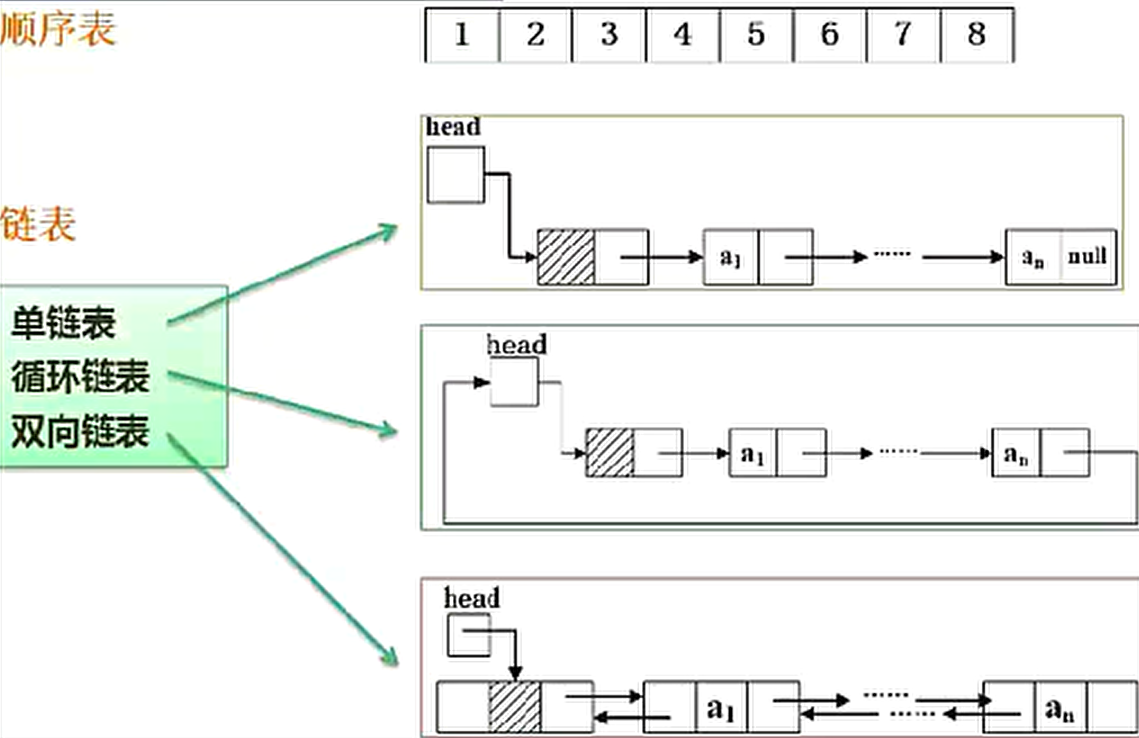
线性结构:每个元素 最多只有一个出度和一个入度,表现为一条线状。线性表 按存储方式分为顺序表和链表
存储结构:
-
顺序存储:用一组地址连续的存储单元依次存储线性表中的数据元素,使得逻辑上相邻的元素物理上也相邻。
-
链式存储:存储各数据元素的结点的地址并不要求是连续的,数据元素逻辑上相邻,物理上分开。
顺序存储和链式存储对比
- 在空间方面,因为 链表还需要存储指针,因此有空间浪费存在。
- 在时间方面,当 需要对元素进行破坏性操作(插入删除)时,链表效率最高,因为只需要修改指针指向即可,而顺序表因为地址是连续的,当删除或插入一个元素后,后面的其它结点位置都需要变动。
- 而当需要对元素进行 不改变结构操作时(读取、查找),顺序表效率更高,因为其物理地址是连续的,如同数组一样,只需要按照索引号就可以快速定位,而链表需要从头节点开始,一个个的查找下去。
栈和队列
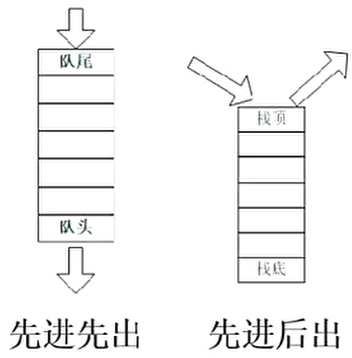
队列、栈结构如上图,队列是先进先出,��分队头和队尾;
栈是先进后出,只有栈顶能进出。
循环队列
设循环队列 Q 的容量为 MAXSIZE,初始时队列为空,且 Q.rear 和 Q.front 都等于 0。
元素入队时修改队尾指针,即令Q.rear=(Q.rear+1)%MAXSIZE。 元素出队时修改队头指针,即令Q.front=(Q.front+1)%MAXSIZE。
根据队列操作的定义,当出队操作导致队列变为空时,有 Q.rear = Q.front ;若入队操作导致队列满 ,则 Q.rear = Q.front
队头指针永远指向队列的第一个元素,队尾指针永远指向最后一个元素的下一个元素。队头指针是为了读操作,所以指向第一个可以读的元素;队尾指针是为了写操作,所以指向空闲区域。
在队列空和队列满的情况下循环队列的队头、队尾指针指向的位置是相同的,此时仅仅根据 Q.rear 和 Q.front 之间的关系无法断定队列的状态。为了区分队空和队满的情况,可采用以下两种处理方式:
- 设置��一个标志,以区分头尾指针相同时队列是空还是满
- 牺牲一个存储单元,约定以 队列的尾指针所指位置的下一个位置是队头指针时,表示队列满;而头尾指针相同时表示队列为空。(Q.rear+1)%MAXSIZE = Q.front。
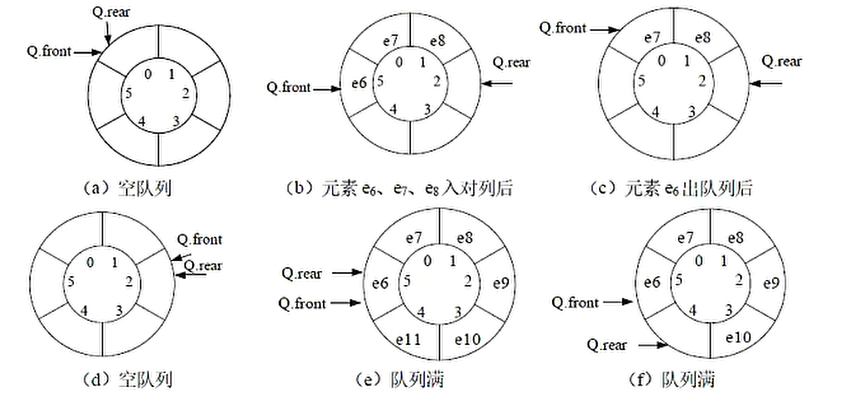
注意队尾指针和队尾元素的指针的区别。
字符串
字符串是一种 特殊的线性表,其数据元素都是字符。。
- 空串:长度为 0 的字符串,没有任何字符。
- 空格串:由 一个或多个空格组成的串,空格是空白字符,占有一个字符长度。
- 子串:串中 任意长度的连续字符构成的序列称为子串,含有子串的串称为主串。
- 串的模式匹配:子串的定位操作,用于 查找子串在主串中第一次出现的位置的算法。
朴素模式匹配算法
- 朴素的模式匹配算法:也称为布鲁特-福特算法,其基本思想是 从主串的第 1 个字符起与模式串的第 1 个字符比较,若相等,则 继续逐个字符进行后续的比较;否则从主串中的第 2 个字符起与模式串中的第一个字符重新比较,直到模式串中的每个字符依次和主串中的一个连续的字符序列相等位置,此时称为匹配成功,否则称为匹配失败。
/**
* 朴素的模式匹配算法
* @param text
* @param pattern
*/
public static int naivePatternMatching(String text, String pattern) {
// 维护主串的匹配位置
int textStart = 0;
while(textStart<=text.length()-pattern.length()){
boolean isMatch = true;
for (int i = 0; i < pattern.length(); i++) {
if (text.charAt(textStart+i)!=pattern.charAt(i)){
isMatch = false;
break;
}
}
if (isMatch){
return textStart;
}
textStart++;
}
return -1;
}
n 是主串的长度,m 是模式串的长度。在主串中,检查起始位置分别是 0、1、2...n-m 且长度为 m 的 n-m+1 个子串,看有没有模式匹配的。
KMP 算法
对基本模式匹配算法的改进,其改进之处在于:每当匹配过程中出现 相比较的字符不相等时,不需要回溯主串的字符位置指针,而是利用 已经得到的“部分匹配”的结果将模式串向右“滑动”尽可能远的距离,再继续进行比较。
当模式串中的字符 与主串中的相应的字符 不相等时,因其前 j 个字符()已经获得了成功的匹配,所以若模式串中“”与“”相同,这时可令 与 进行比较,从而使 i 无需回退。
在 KMP 算法中,依据 模式串的 next 函数值实现子串的滑动。若令 next[j] = k,则 next[j] 表示模式串中的 pj 与主串中相应字符不相等时,令模式串的 next[j] 与主串的相应字符进行比较。
数组
数组、矩阵、广义表要当成新的东西去理解。这里的数组是多维数组。
数组是 定长线性表在维度上的扩展,即 线性表中的元素又是一个线性表。N维数组是一种“同构”的数据结构,其 每个数据元素类型相同、结构一致。
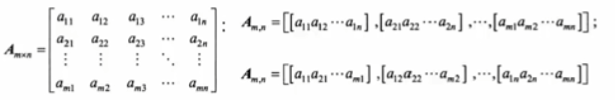
其可以表示为行向量形式或者列向量形式线性表,单个关系最多只有一个前驱和一个后驱,本质还是线性的。
数组结构的特点:数据元素数目固定;数据元素类型相同;数据元素的下标关系具有上下界的约束且下标有序。
数组数据元素固定,一般不做插入和删除运算,适合采用顺序结构
数组存储地址的计算,特别是二维数组,要注意理解,假设每个数组元素占用存储长度为 len,起始地址为 a,存储地址计算如下(默认从 0 开始编号)
| 数组类型 | 存储地址计算 |
|---|---|
| 一维数组a[n] | a[i]的存储地址为:a+i*len |
| 二维数组a[m][n](按行存储) | a[i][j]的存储地址为a+(i*n+j)*len |
| 二维数组a[m][n](按列存储) | a[i][j]的存储地址为a+(j*m+i)*len |
矩阵
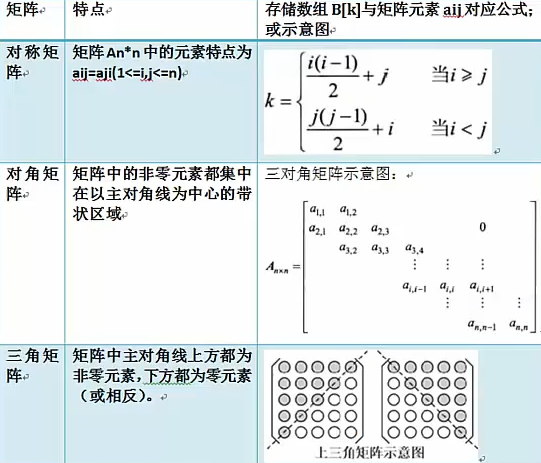
特殊矩阵:矩阵中的元素(或非0元素)的分布具有一定的规律。常见的特殊矩阵有对称矩阵、三角矩阵和对角矩阵。
稀疏矩阵:在一个矩阵中,若非零元素的个数远远少于零元素个数,且非零元素的分布没有规律。
存储方式为三元组结构,即 存储每个非零元素的(行、列、值)
广义表(几乎不考)
广义表是线性表的推广,是由 0个或多个单元素或子表组成的有限序列。
广义表与线性表的区别:线性表的元素都是结构上不可分的单元素,而广义表的元素 既可以是单元素,也可以是有结构的表。
广义表一般记为:LS=(α1,α2,...,αn):其中 LS 是表名,ai 是表元素,它可以是表(称为子表),也可以是数据元素(称为原子)。其中 n 是 广义表的长度(也就是最外层包含的元素个数),n = 0 的广义表为空表;而 递归定义的重数就是广义表的深度,即定义中所含括号的重数(包括括号的个数,原子的深度为0,空表的深度为 1).
head() 和 tail() : 取表头(广义表第一个表元素,可以是子表也可以是单元素)和取表尾(广义表中,除了第一个表元素之外的其它所有表元素构成的表,非空放仪表的表尾必定是一个表,即使表尾是氮元素)操作。