基础
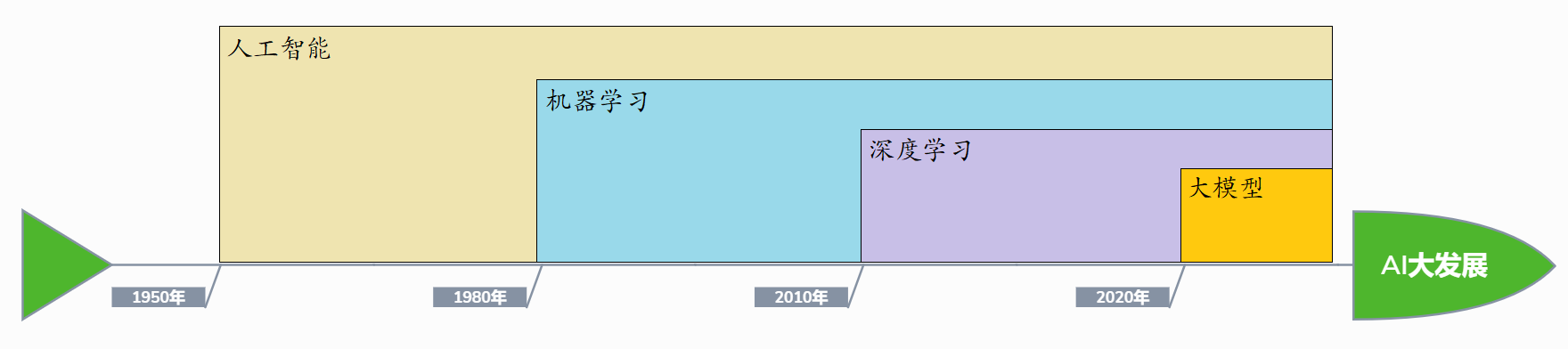
AI 历史上的四次大发展
机器学习
定义
人工智能是一个抽象的概念,机器学习是实现人工智能的一种途径,从数据中分析获得规律,并利用规律对未知数据进行预测、分类或者决策的过程。
核心流程
| 步骤 | 说明 |
|---|---|
| 1. 准备样本 | 找到大量样本(如 1 万张汽车图片) |
| 2. 提取特征 | 对样本提取特征(高度、颜色、发动机等) |
| 3. 选择算法 | 选择现成的数学公式/模型(CNN 等) |
| 4. 训练模型 | 将特征数据交给算法学习,获得规律 |
| 5. 预测输出 | 将未知样本特征交给模型,得出结论 |
案例:汽车识别
- 选择算法(用算法):调用现成的 CNN 模型,如
torchvision.models.resnet50() - 训练模型(训练算法):准备 10 万张标注好的图片,喂给模型,调整学习率等超参数
- 使用训练好的模型(上菜):保存训练好的模型,如
my_car_detector.pth,加载后即可判断
流程图
输入数据(数据集)
↓
算法/模型(数学公式)
↓
训练(调整参数)
↓
输出结果(预测/分类/决策)
深度学习
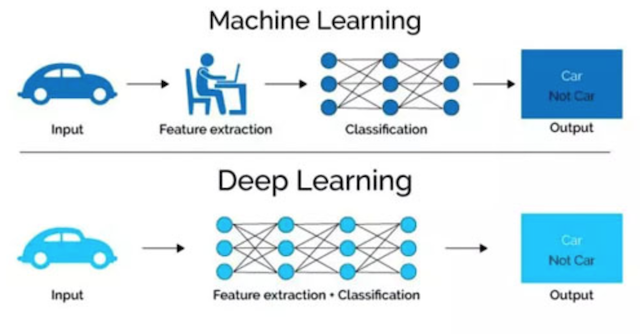
与机器学习的区别
| 维度 | 机器学习 | 深度学习 |
|---|---|---|
| 特征工程 | 手动完成,需要领域专业知识 | 自动提取,无需人工设计 |
| 模型结构 | 通常为单层或简单结构 | 多层神经网络,自动学习特征 |
| 数据依赖 | 较少数据即可 | 需要大量数据 |
深度学习通常由多个层组成,将更简单的模型组合在一起,通过大量数据的训练自动得到模型。
应用场景
图像识别:
- 物体识别、场景识别、车型识别
- 人脸检测跟踪、人脸关键点定位、人脸身份认证
自然语言处理:
- 机器翻译、文本识别、聊天对话
语音技术:
- 语音识别
神经网络
定义
神经网络(Neural Network,NN)是深度学习的重要算法,全称人工神经网络(ANN),是一种模仿生物神经网络结构,和功能的计算模型。
神经元
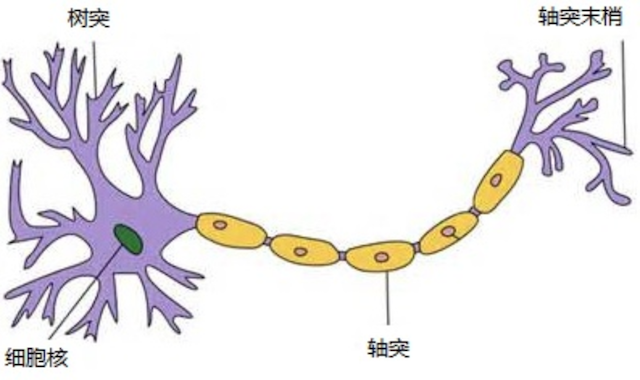 人脑由神经元组成:
人脑由神经元组成:
- 树突:接受传入信息
- 细胞核:接收信号并处理
- 轴突:将处理结果传出
- 突触:神经元之间的连接位置
网络结构
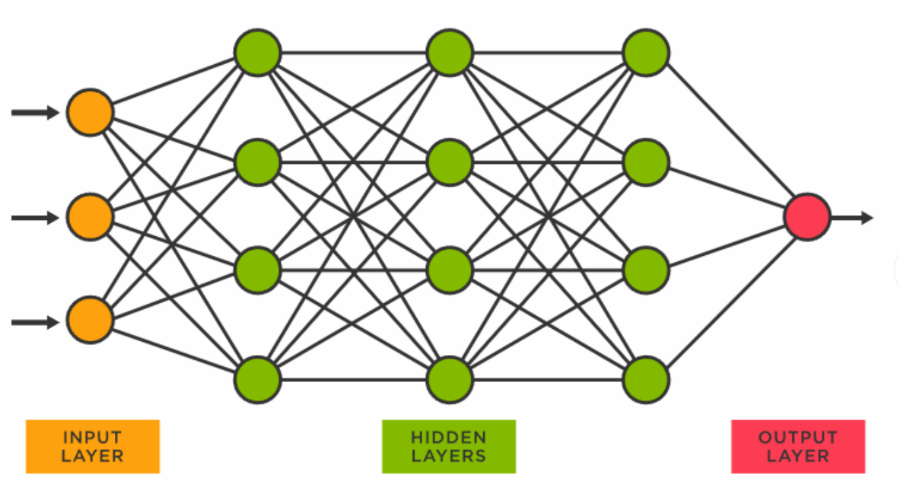
输入层 → 隐藏层 → 输出层
| 层 | 说明 |
|---|---|
| 输入层 | 输入数据 |
| 隐藏层 | 可为多层,多少层都可以 |
| 输出层 | 输出结果 |
推荐体验:TensorFlow Playground - 谷歌神经网络可视化网站
大语言模型
定义
大语言模型(Large Language Model,LLM)是专门设计用于自然语言处理领域的特殊深度神经网络。
特点
| 特点 | 说明 |
|---|---|
| 训练数据大 | 使用海量文本数据进行训练 |
| 规模大 | 参数规模巨大(数十亿到万亿级) |
| 算力大 | 需要大量 GPU/TPU 计算资源 |
| 泛化能力强 | 预训练模型具备广泛任务能力 |
为什么近几年大模型兴起
| 因素 | 说明 |
|---|---|
| 硬件进步 | GPU、TPU 等高性能计算设备普及 |
| 算法优化 | Transformer 架构提出,提升长序列处理能力 |
| 数据爆炸 | 互联网文本、图像、视频数据激增 |
| 分布式训练 | PyTorch、TensorFlow 等框架成熟 |
常见大模型
| 模型 | 公司 | 开源/闭源 | 主要特点 |
|---|---|---|---|
| DeepSeek | 深度求索 | 开源 | 强大推理与 Agent 能力,完全免费 |
| 通义千问 | 阿里巴巴 | 开源 | 顶级开源编程模型,超大上下文 |
| 文心4.5 | 百度 | 开源 | 多模态 MoE 架构,高效训练推理 |
| 豆包 | 字节跳动 | 部分开源 | 商业化导向,强调性价比 |
| 腾讯混元 | 腾讯 | 部分开源 | 多模态与 3D 生成能力突出 |
| Kimi K2 | 月之暗面 | 开源 | 强大思考与浏览能力 |
| GPT 系列 | OpenAI | 主要闭源 | 行业标杆,集成智能体能力 |
| Claude 系列 | Anthropic | 闭源 | 注重安全与对齐,长上下文 |
| LLaMA 系列 | Meta | 开源 | 全球最主流开源模型基石 |
| Gemini 系列 | 主要闭源 | 原生多模态设计 |
开源 vs 闭源
| 开源大模型 | 闭源大模型 |
|---|---|
| ✅ 代码、数据、训练流程公开 | ❌ 黑箱操作,无法验证内部逻辑 |
| ✅ 支持微调、领域适配 | ❌ 仅限 API 功能,无法修改模型 |
| ✅ 可本地部署,长期成本固定 | ❌ 按使用量付费,大规模应用成本高 |
| ⚠️ 受限于社区资源 | ✅ 依托大厂算力与数据,能力更强 |
| ⚠️ 需自行管理基础设施 | ✅ 供应商负责运维 |
| ✅ 数据完全本地化,满足隐私要求 | ❌ 依赖第三方 API,存在泄露风险 |
通用基础大模型 vs 行业垂直大模型
| 类型 | 说明 |
|---|---|
| 通用基础大模型 | 通用的基础能力,适用于各种任务 |
| 行业垂直大模型 | 在通用模型基础上,训练专业垂直领域模型 |
当前 60% 的企业通过垂类行业大模型实现 AI 在行业的应用布局。
大模型微调
当模型在某些领域不专业时,可以进行微调:
下载预训练模型 → 准备训练数据集 → 使用 LLaMA-Factory 框架训练 → 测试
大模型应用与趋势
应用领域
金融、医疗、工业、教育、科研、媒体、通信、政务、营销、交通、文娱、城市治理、传媒、法律、汽车、校对、运维等各行各业。
典型场景
智能客服、智能搜索、智能营销、智能问答、智能风控、虚拟数字人、代码助手、智慧办公、资产管理、产品研发、政务咨询、业务办理、舆情监控、公文写作、智慧医疗、健康诊疗知识库等。
发展趋势
技术突破:
- 模型规模进一步扩大
- 模型效率提升
- 多模态能力增强
- 可解释性和透明性提升
应用落地:
- 定制化和专用化,行业大模型爆发
- 边缘端部署
- UGC + AIGC 生态融合
挑战
| 挑战 | 说明 |
|---|---|
| 安全问题 | 伦理安全、数据治理、人机协作 |
| 均衡问题 | 资源消耗、环境影响、技术普及不均衡 |