从函数到神经网络
核心思想演进路线
函数 → 符号主义 → 联结主义 → 神经网络
一切皆函数
基本信念
早期的人工智能相信,这个世界上的所有逻辑或知识,都可以用一个函数来表示。
作用流程

现实世界(x) --[符号化]--> f(x) --[规则]--> y --[解释]--> 现实世界
举例
| 输入 | 函数(规则) | 输出 |
|---|---|---|
| 直角三角形两边长 a, b | 勾股定理 | 斜边长度 c |
| 质量 m、加速度 a | 牛顿第二定律 F = ma | 作用力 F |
早期 AI 思路:符号主义
人工智能早期的思路——符号主义。
核心思想
人类试图为各种任务编写明确的函数规则。
面临的困境
| 任务 | 符号主义思路 | 实际困难 |
|---|---|---|
| 图像识别 | 编写识别狗的规则 | 规则复杂到无法编写 |
| 机器翻译 | 语�法规则 + 词典 | 无法做到丝滑自然 |
这条路走到头了。很多问题,人类实在是想不出怎么写成一个明确的函数。
现代 AI 思路:联结主义
既然不知道这个函数长什么样,那就换个思路。
核心思想
从已知数据 (x, y),反向推导出函数关系。
两大法宝
| 口诀 | 含义 |
|---|---|
| 假设 | 先假设一个函数形式(如 y = wx + b),然后根据数据调整参数 |
| 近似 | 不追求完美匹配,允许存在误差,追求足够接近即可 |
举例
已知数据点:
| x | y |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 3 | 6 |
| 4 | 8 |
→ 猜测函数 y = 2x(符号主义思路,一眼看穿)
但如果是这样的数据:
| x | y |
|---|---|
| 2 | 2 |
| 3 | 2.5 |
| 4 | 3 |
| 5 | 3.5 |
→ 就需要用"假设 + 近似"的方法,通过调整 w 和 b,让直线逐渐逼近数据点。
两大 AI 范式对比
| 维度 | 符号主义 | 联结主义 |
|---|---|---|
| 核心目标 | 寻找宇宙真理的万能公式 | 找到足够接近真实答案的近似解 |
| 方法 | 人为定义规则 | 通过数据拟合(假设 + 近似) |
| 局限性 | 遇到复杂任务(如图像识别)无法编写规则 | 需要大量数据和计算 |
| 方法论 | 人类设计规则(精心设计菜谱) | 数据驱动(基于统计学习逐渐逼近) |
引入非线性:激活函数
问题
线性函数 f(x) = wx + b 只能拟合直线关系,对于曲线分布的数据无能为力。
解决方案
在函数外层套一层非线性运算:
f(x) = g(wx + b)
其中 g 为激活函数。
常用激活函数
| 激活函数 | 公式 | 特点 |
|---|---|---|
| Sigmoid | σ(z) = 1 / (1 + e⁻ᶻ) | S 形曲线,压缩到 0-1 之间 |
| ReLU | max(0, z) | 小于 0 归 0,大于 0 保留,计算高效 |
| 平方 | (wx + b)² | 非线性变换 |
| 正弦 | sin(wx + b) | 周期性的非线性变换 |
激活函数的目的,是将线性关系转换为非线性关系,增强模型的表达能力。
神经网络的构建
1. 为什么需要转换?
| 问题 | 说明 |
|---|---|
| 公式太复杂 | 多层嵌套的函数写出来很长,普通人看个两层脑子就炸了 |
| 不直观 | 很难直观理解数据在层层变换中发生了什么 |
| 图形更直观 | 把函数画成"圆圈 + 箭头"的图形,一眼就能看清结构 |
把函数画成神经网络这种形式,就是为了更直观地理解复杂的嵌套变换。
2. 函数到神经网络的映射
| 函数形式 | 神经网络形式 |
|---|---|
| 每个变量 x | 输入层的每个节点 |
| 线性变换 wx + b | 神经元节点(接收输入、加权求和) |
| 激活函数 g() | 节点上的非线性运算 |
| 多层嵌套 | 多层神经元(隐藏层) |
核心思想:把公式中的每一步运算,对应到神经网络的每一个节点上。
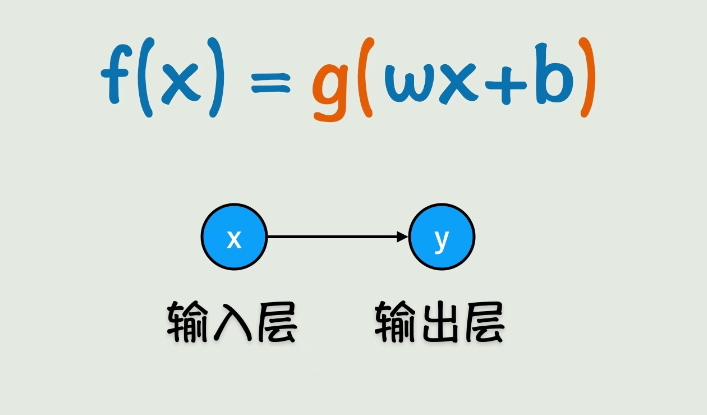
3. 分阶段构建
神经网络的构建遵循一个核心原则:不断嵌套、不断扩展。
阶段一:单输入 → 单层网络
f(x) = g(wx + b)
输入层(x) → 输出层(y)
阶段二:多输入扩展
f(x₁, x₂) = g(w₁x₁ + w₂x₂ + b)
输入层(x₁, x₂) → 输出层(y)
每个输入 x 对应一个权重 w,多输入需要分别加权求和。
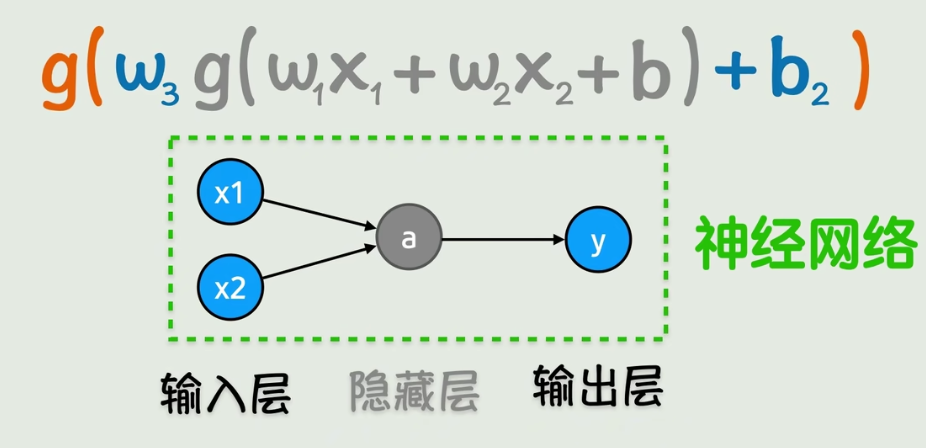
阶段三:多层嵌套 → 引入隐藏层
f(x₁, x₂) = g(w₃ · g(w₁x₁ + w₂x₂ + b₁) + b₂)
输入层(x₁, x₂) → 隐藏层(a) → 输出层(y)
为什么需要多层? 只套一层激活函数,曲线弯曲得还不够灵活,表达能力有限。需要再进行一次线性变换 + 激活函数,可以无限套娃。
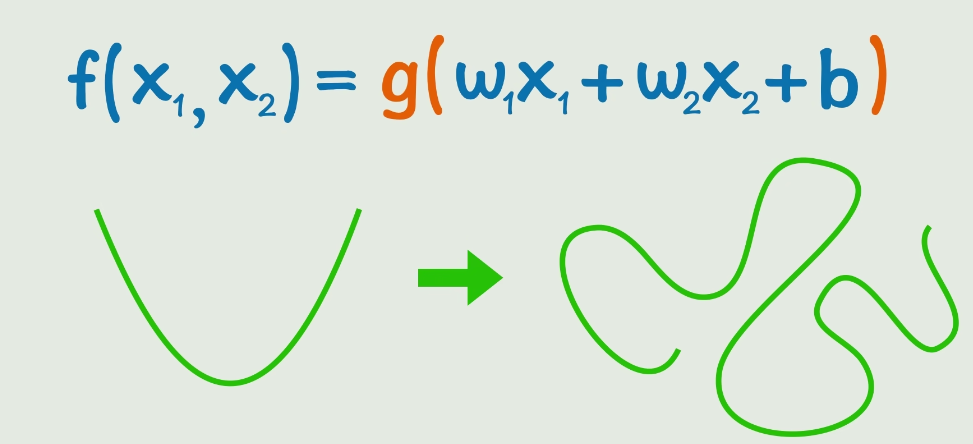
构建演变
单层:y = g(wx + b)
↓ 增加输入
多层:y = g(w₁x₁ + w₂x₂ + b)
↓ 嵌套激活
深层:y = g(w₃ · g(w₁x₁ + w₂x₂ + b₁) + b₂)
↓ 无限扩展
复杂网络:...
通过不断堆叠线性变换 + 激活函数,可以理论上逼近任意连续函数(万能近似定理)。
4. 基本概念
| 概念 | 说明 |
|---|---|
| 神经元 (Node) | 神经网络中的圆圈,对应一个数学运算单元(不建议类比生物神经元) |
| 输入层 | 接收原始输入数据 |
| 隐藏层 | 中间层,进行复杂特征变换 |
| 输出层 | 输出最终结果 |
| 前向传播 | 信号从输入层 → 隐藏层 → 输出层的单向传播过程 |
5. 网络规模
| 维度 | 可以无限增加 |
|---|---|
| 每层神经元数量 | ✅ |
| 隐藏层层数 | ✅ |
虽然对应的函数表达式会变得极其复杂,但网络结构始终清晰直观。
神经网络的训练
问题引入
已知大量的输入 x 和对应的真实标签 y(训练数据),如何求解网络中的 w 和 b?
核心三要素
| 要素 | 说明 | 作用 |
|---|---|---|
| 损失函数 | 衡量模型预测值与真实值之间的差距 | 定义优化目标 |
| 梯度下降 | 通过求导找到参数调整的方向 | 参数优化算法 |
| 反向传播 | 基于链式法则计算梯度 | 高效计算梯度 |
1. 损失函数
定义:衡量单个样本的预测值与真实值之间的差距。
| 损失函数 | 公式 | 适用场景 |
|---|---|---|
| MSE(均方误差) | 回归问题 | |
| 交叉熵 | 分类问题 |
2. 梯度下降
核心思想:沿着损失函数下降最快的方向,一步一步调整参数。
损失函数 L(w)
↓
计算梯度 ∂L/∂w(告诉参数该往哪个方向走)
↓
更新参数 w = w - α · ∂L/∂w(α 为学习率)
↓
重复直到损失足够小
| 参数 | 说明 |
|---|---|
| 学习率 α | 每��次更新的步长,太大容易震荡,太小收敛慢 |
3. 反向传播
核心思想:从输出层到输入层,逐层计算梯度并更新参数。
前向传播:输入 → 隐藏层 → 输出(计算预测值)
↓
计算损失:L = loss(预测值, 真实值)
↓
反向传播:输出层 → 隐藏层 → 输入层(计算梯度)
↓
更新参数:w = w - α · 梯度
反向传播利用链式法则,将输出层的损失一层一层传回去,高效计算每个参数的梯度。
总结
早期人工智能相信,可��以找到精确的函数来表示一切,但因为这个世界实在太复杂了,所以人们就放弃了。转向了寻找一个足够接近真实答案的近似解。
线性关系太过于简单,不足以描述更复杂的关系,于是引入了非线形的激活函数,通过线形变换和非线性激活函数的不断组合和套娃可以表达很复杂的关系。
但是复杂函数表达式难以直观理解,于是就画成了神经网络这种形式。
神经网络的本质就是线形变换,套上一个激活函数,然后不断的组合和套娃,就成为了一个非常复杂的非线形函数,目的就是计算 w 和 b ,使得这个函数能够很好的拟合真实数据。