计算神经网络的参数
核心问题
神经网络其实就是线形变换,套上一个激活函数,然后不断的组合和套娃,就成为了一个非常复杂的非线形函数。
核心目标:找到一组 w 和 b,使这个函数可以很好地拟合真实数据。
什么是好的参数?
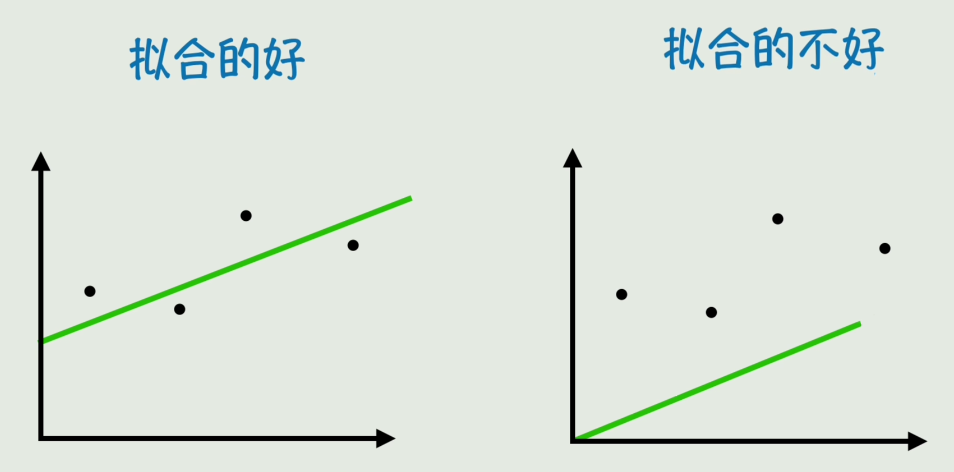
直观理解
| 情况 | 说明 |
|---|---|
| 拟合得好 | 直线穿过散点中间,预测值接近真实值 |
| 拟合得不好 | 直线远离散点,预测值与真实值差距大 |
数学表达
用数学语言描述"拟合好坏":
| 符号 | 含义 |
|---|---|
| y | 真实数据 |
| ŷ (y hat) | 预测数据(直线上的点) |
| |y - ŷ| | 单个误差 |
| Σ|yᵢ - ŷᵢ| | 总误差 |
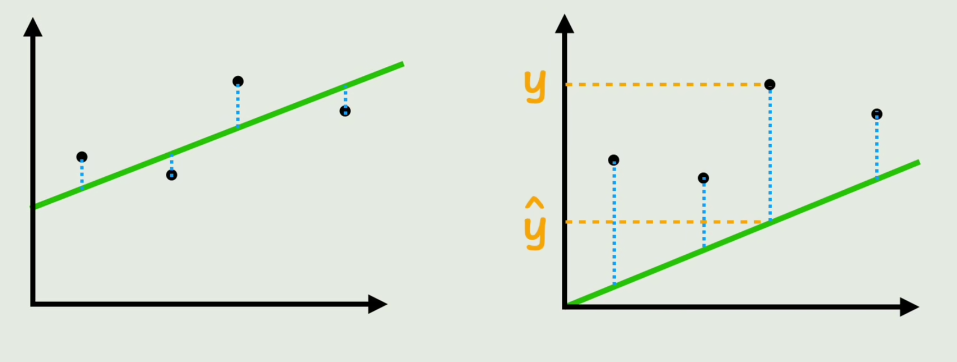
将所有误差加起来,就反映了当前函数与真实数据的拟合度。
损失函数
定义
损失函数:衡量模型预测值与真实值之间差距的函数。
均方误差 (MSE)
最常用的损失函数之一:
| 步骤 | 公式 | 说明 |
|---|---|---|
| 原始 | Σ|yᵢ - ŷᵢ| | 带绝对值,数学优化不友好 |
| 改造 | Σ(yᵢ - ŷᵢ)² | 用平方代替绝对值 |
| 最终 | L(w, b) = (1/N) Σ(yᵢ - ŷᵢ)² | 除以 N 取平均 |
改造原因:
- 绝对值不平滑,数学优化时不方便
- 平�方放大了误差较大的值的影响
- 除以 N 消除样本数量的影响
 最终得到的这个公式,就叫做均方误差。
最终得到的这个公式,就叫做均方误差。
目标
找到让损失函数 L(w, b) 最小的 w 和 b:
min L(w, b)

简单情况:线性回归
例子
数据:(1,1), (2,2), (3,3), (4,4) 模型:y = wx(简化为过原点) 目标:求让 L 最小的 w
求解过程
1. 展开损失函数:
L(w) = (1/4)[(1-w)² + (2-2w)² + (3-3w)² + (4-4w)²]
2. 化简:
L(w) = 7.5 - 15w + 7.5w²
3. 求导:
L'(w) = -15 + 15w
4. 令导数为 0:
w = 1
5. 结果:y = x
一般情况:偏导数
当模型为 y = wx + b 时,需要两个参数:
∂L/∂w = 0
∂L/∂b = 0
偏导数:对 w 求偏导,就是把 b 当做常数,和一元函数求导一样。
复杂情况:梯度下降
问题
神经网络的损失函数是非线性函数,不能直接通过求导等于 0 来得到解析解。
解决思路
一点点试 —— 不断调整参数,观察损失函数变化,直到足够小。
演示
| 步骤 | 操作 | L 结果 | 判断 |
|---|---|---|---|
| 初始 | w=5, b=5 | L=10 | - |
| 试 | w=6(增加1) | L=9 | 方向对,继续增加 w |
| 试 | b=6(增加1) | L=11 | 方向反了,减少 b |
| 试 | b=3 | L=7 | 方向对了 |
| ... | ... | ... | 循环直到 L 足够小 |
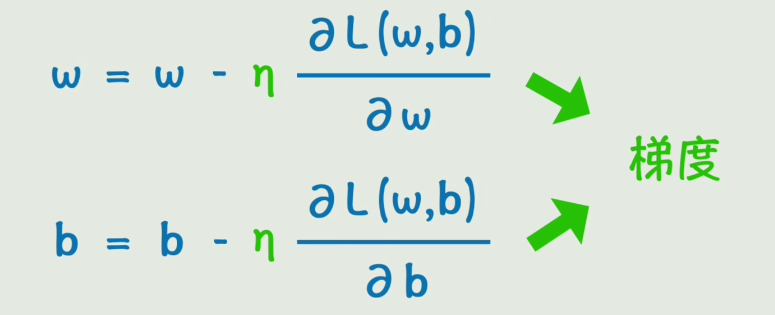
梯度下降公式
w = w - η · ∂L/∂w
b = b - η · ∂L/∂b
| 参数 | 说明 |
|---|---|
| η (eta) | 学习率,控制每次更新的步长 |
| ∂L/∂w | 损失函数对 w 的偏导数,即梯度 |
本质
| 概念 | 说明 |
|---|---|
| 梯度 | 由所有偏导数构成的向量 |
| 梯度下降 | 沿着梯度的反方向,逐渐减小损失函数,求出 w 和 b 的过程 |
反向传播
关键问题
神经网络中,偏导数该如何计算?
链式法则
核心思想:复杂偏导数可以分解为多个简单偏导数的乘积。
∂L/∂w₁ = ∂L/∂ŷ · ∂ŷ/∂a · ∂a/∂w₁
| 步骤 | 含义 |
|---|---|
| ∂a/∂w₁ | w₁ 变化一个单位,a 变化多少 |
| ∂ŷ/∂a | a 变化一个单位,ŷ 变化多少 |
| ∂L/∂ŷ | ŷ 变化一个单位,L 变化多少 |
| 乘积 | w₁ 变化一个单位,L 变化多少 |
可以联��想齿轮传动:第一个齿轮转一圈,最后一个齿轮转多少?乘起来就是了。
网络结构示例
输入 x → [隐藏层 a] → [输出层 ŷ] → 损失 L
x --(w₁,b₁)--> a = g(w₁x + b₁) --(w₂,b₂)--> ŷ = g(w₂a + b₂) --(y-ŷ)²--> L
训练过程
| 阶段 | 说明 |
|---|---|
| 前向传播 | 根据输入 x 计算输出 ŷ 和损失 L |
| 反向传播 | 从输出层到输入层,逐层计算梯度 |
| 参数更新 | 每个参数都向梯度的反方向变化 |
不断前向传播、反向传播,构成神经网络的训练过程。
六、总结
核心概念
| 概念 | 说明 |
|---|---|
| 损失函数 | 衡量预测值与真实值的差距,如均方误差 MSE |
| 线性回归 | 通过求导等于0直接得到 w 和 b |
| 梯度下降 | 无法直接求解时,一点点试,偏导数的反方向调整 |
| 链式法则 | 复杂偏导数分解为多个简单偏导数的乘积 |
| 反向传播 | 通过链式法则逐层计算梯度并更新参数 |
训练的本质
前向传播:输入 → 计算输出和损失
↓
反向传播:计算每个参数的梯度
↓
参数更新:w = w - η · 梯度
↓
循环直到损失足够小
神经网络经过多轮训练,参数一点点变化,直到找到让损失函数足够小的 w 和 b。
为了找到一组 w 和 b 来拟合真实数据。定义了损失函数,通过制定让损失函数最小化这个目标来计算 w 和 b 的值。
由于神经网络的复杂性,没有办法直接得到 w 和 b 的解析解,只能通过一点点往偏导数的反方向调整每个参数,来慢慢接近真实答案,这个方法就叫做梯度下降。
而由于神经网络的层数较多,直接求偏导数比较困难,所以可以逐层求导,间接得到最终的偏导数,这就是链式法则。
通过链式法则求导并逐层更新参数这个过程就叫做反向传播。
不断的前向传播,反向传播,这就构成了神经网络的训练过程。