LlamaIndex 框架介绍
大模型开发框架概述
核心价值:降低开发、维护成本,让开发者更方便地构建基于大语言模型的应用。
框架提供的核心能力
| 能力类型 | 说明 | 示例 |
|---|---|---|
| 第三方能力抽象 | 统一接口封装外部服务 | LLM、向量数据库、搜索接口 |
| 常用工具封装 | 开箱即用的工具和方案 | 文档解析、数据分块、检索优化 |
| 底层实现封装 | 处理复杂的底层逻辑 | 流式接口、超时重连、异步并行 |
优秀框架的特征
- 可靠性高:合法输入不会引发框架内部报错
- 可维护性高:经常变的部分(如 Prompt 模板)在外部维护
- 可扩展性高:可随意更换 LLM 或第三方工具,无需大量重构
- 学习成本低:API 设计直观,文档完善
选对框架,事半功倍;选错框架,事倍功半。
LlamaIndex 框架介绍
LlamaIndex 是专注于上下文增强的大语言模型应用开发框架,适用于在私有或特定领域数据基础上构建 LLM 应用。
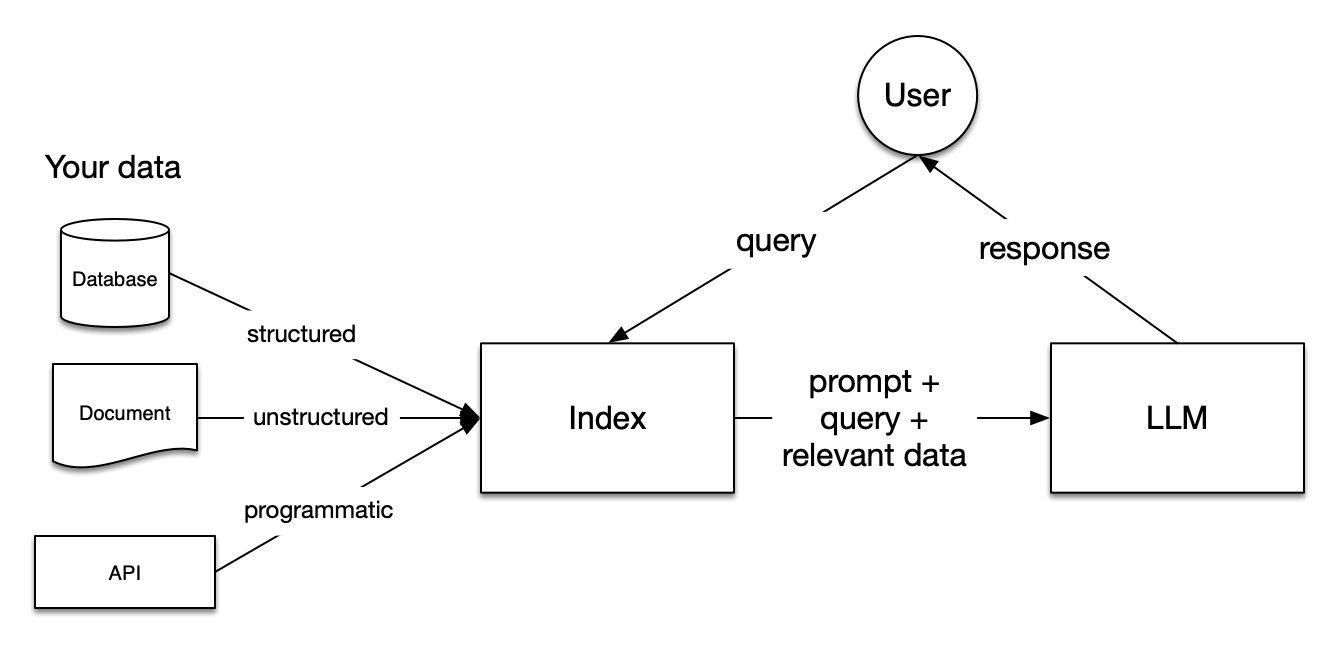
版本与文档
| 版本 | 文档地址 | API 文档 |
|---|---|---|
| Python(推荐) | docs.llamaindex.ai | API Reference |
| TypeScript | ts.llamaindex.ai | API Reference |
- 开源仓库:github.com/run-llama
核心模块架构
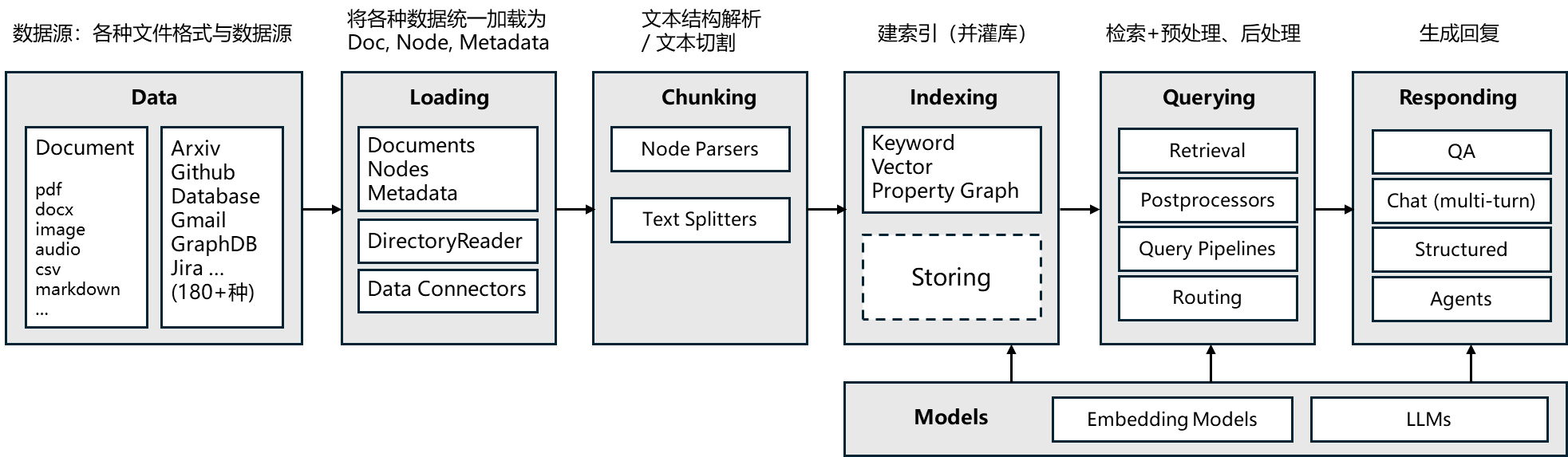
框架对比:LangChain vs LlamaIndex
| 对比维度 | LangChain | LlamaIndex(原 GPT Index) |
|---|---|---|
| 定位与设计 | 通用型 LLM 应用框架(可构建 Agent、Tool、RAG 等各种系统) | 专注文档理解与 RAG 的索引、检索、问答框架 |
| 核心理念 | "链式调用(Chains)" 和 "工具组合(Tools)",强调可编排性 | "数据接口(Data Index + Query Engine)",强调数据到知识的映射 |
| 文档加载能力 | DocumentLoader支持多格式文档(PDF、HTML、TXT) | 深度集成解析器(如 LlamaParse、Unstructured、PandasReader) |
| 数据解析深度 | 主要提取纯文本,结构化需手动实现 | 提供高层结构抽象(Document → Node → Index),保留层级关系 |
| 索引结构 | VectorStore(Chroma、FAISS、Milvus等)为核心,开发者需手动管理 | 提供多种索引:VectorStoreIndex, SummaryIndex, KnowledgeGraphIndex |
| 上下文压缩 / rerank | 需额外配置 Reranker 或 ContextCompressor | 原生支持 Context Compression / Node PostProcessor |
| 多文档检索 | 可通过 MultiQueryRetriever、 ParentDocumentRetriever实现 | 内置 ComposableGraph实现多索引融合检索 |
| Agent 能力 | 强(LangChain 是 Agent 生态核心框架) | 弱(更偏向数据检索与知识问答) |
| 生态与扩展性 | 最大的 LLM 生态,插件、工具链最丰富 | 与数据密集型 RAG 项目结合最紧(适合文档知识库类应用) |
| 适用场景 | 多步骤推理、Agent系统、工具调用、企业助手 | 文档问答、知识检索、企业知识库、研究型报告分析 |
| 示例语法简洁度 | 代码偏工程风格,组件组装较多 | 封装层高,一行代码即可构建 query engine |
| 性能优化方向 | 优化在链路编排与检索召回效率 | 优化在文档解析、chunk 切分与上下文压缩 |
| 代表项目 | Chatbot、智能助理、Agent系统、数据问答 | 企业知识库问答、PDF报告分析、学术RAG系统 |
核心定位差异:
- LangChain = 逻辑大脑:强在工作流编排、Agent 化、工具集成
- LlamaIndex = 知识记忆:强在文档结构化、RAG 索引、检索优化
- 两者是 RAG 系统的天然组合,互补而非竞争
环境准备
核心库安装
LlamaIndex版本0.14.x
pip install llama-index-core llama-index
解析库安装
pip install llama-parse unstructured nest-asyncio python-multipart llama-index-readers-file
pip install pytest
pip install "unstructured[md]"
常用文档解析组件
| 组件 | 适用场景 | 说明 |
|---|---|---|
SimpleDirectoryReader | 简单文档读取 | 快速读取目录下的文档 |
LlamaParse | 复杂 PDF 解析 | 针对复杂布局、表格的 PDF |
UnstructuredReader | 多格式文档 | 支持 PDF、DOCX、HTML 等 |
PandasReader | 表格类文件 | Excel、CSV 等结构化数据 |
LlamaParse API Key 申请:llamaindex.org.cn/blog/pdf-parsing-llamaparse
基础使用示例
from llama_index.core import SimpleDirectoryReader
from llama_parse import LlamaParse
# 如果文档结构复杂,优先使用 LlamaParse
# parser = LlamaParse(api_key="YOUR_LLAMA_CLOUD_API_KEY")
# documents = parser.load_data("sample.pdf")
# 或者使用简单读取器
documents = SimpleDirectoryReader(input_files=["RAG评估.md"]).load_data()
print(documents[0].metadata)
print("===========================")
print(documents[0].text)
print("===========================")
LlamaIndex 集成 Unstructured
框架定位
| 框架 | 定位 | 核心职责 |
|---|---|---|
| LlamaIndex | 知识管理层 | 结构化管理与大模型交互的外部知识(索引、检索、问答) |
| Unstructured | 文档提取层 | 将复杂格式(PDF、DOCX、HTML 等)解析成统一的文本元素 |
集成方式对比
| 对比点 | UnstructuredReader | partition 直接解析 |
|---|---|---|
| 底层调用 | 封装了 partition(),简化调用 | 直接调用 partition() API |
| 灵活度 | 部分参数隐藏,仅暴露常用接口 | 可访问所有底层参数(strategy、OCR、语言等) |
| 可控性 | 自动化程度高,定制难度大 | 可自定义处理流程(过滤、正则、chunk 策略) |
| 集成便捷性 | 自动输出 Document 列表 | 需手动转换为 Document |
| 适用场景 | 快速原型/小规模项目 | 生产级 RAG/多格式数据管线/高可控性需求 |
UnstructuredReader
优点:写法极简,自动生成 Document 对象
缺点:无法细调 OCR、chunk_size、文本清洗
from llama_index.readers.file.unstructured import UnstructuredReader
from pathlib import Path
reader = UnstructuredReader()
documents = reader.load_data(file=Path("甬兴证券-AI行业点评报告:海外科技巨头持续发力AI,龙头公司中报业绩亮眼.pdf"))
print("打印列表长度:" + str(len(documents)))
print("==================================")
print("打印解析的文本内容:" + documents[0].text[:100])
print("==================================")
print("�打印元数据信息:" + str(documents[0].metadata))
partition 直接解析
优点:可自由控制解析策略(OCR、chunk、去噪、正则),易于扩展
from unstructured.partition.auto import partition
# 使用LlamaIndex的Document对象,将解析后的元素转换为Document对象
from llama_index.core import Document
# 使用partition函数自动检测文件类型并解析
elements = partition(
filename="甬兴证券-AI行业点评报告:海外科技巨头持续发力AI,龙头公司中报业绩亮眼.pdf",
strategy="hi_res",
split_pdf_page=True,
infer_table_structure=True,
languages=["eng","chi_sim"])
# 将解析后的元素转换为Document对象
docs = [
Document(text=e.text,
metadata={"source":"甬兴证券-AI行业点评报告:海外科技巨头持续发力AI,龙头公司中报业绩亮眼.pdf",
"type": e.category})
for e in elements]
混合方案
策略:根据文件类型智能选择解析方式
- 复杂文件(PDF、图片、DOCX、PPT、Excel)→ 使用
partition()高精度解析 - 简单文件(TXT、MD、CSV、HTML、JSON)→ 使用
UnstructuredReader快速处理
from llama_index.readers.file.unstructured import UnstructuredReader
from unstructured.partition.auto import partition
from llama_index.core import Document
from pathlib import Path
def smart_load(file_path):
"""智能文档加载器:根据文件类型选择最佳解析策略"""
file_path = Path(file_path)
file_ext = file_path.suffix.lower()
# 复杂文件类型(需要高精度解析)
complex_types = {'.pdf', '.png', '.jpg', '.jpeg', '.gif', '.bmp',
'.tiff', '.docx', '.doc', '.pptx', '.ppt', '.xlsx', '.xls'}
if file_ext in complex_types:
print(f"检测到复杂文件类型 {file_ext},使用 partition 高精度解析")
try:
elements = partition(
filename=str(file_path),
strategy="hi_res",
languages=["eng", "chi_sim"],
infer_table_structure=True
)
return [Document(text=e.text, metadata={
"source": str(file_path),
"element_type": type(e).__name__,
"file_type": file_ext
}) for e in elements if e.text.strip()]
except Exception as e:
print(f"高精度解析失败,回退到 Reader: {e}")
reader = UnstructuredReader()
return reader.load_data(file=file_path)
else:
print(f"检测到简单文件类型 {file_ext},使用 Reader 解析")
try:
reader = UnstructuredReader()
return reader.load_data(file=file_path)
except Exception as e:
print(f"Reader 解析失败,回退到 partition: {e}")
elements = partition(filename=str(file_path), strategy="auto")
return [Document(text=e.text, metadata={"source": str(file_path)}) for e in elements]
使用示例:
documents = smart_load("甬兴证券-AI行业点评报告:海外科技巨头持续发力AI,龙头公司中报业绩亮眼.pdf")
最佳实践总结:
- 原型阶段:使用
UnstructuredReader,快速验证想法 - 生产阶段:直接集成
unstructured.partition,获得完全控制 - 混合方案:90% 文件走 Reader,特殊格式回退到
partition
基础索引案例实现
核心流程
PDF 文档需要先转换成带标签的 Markdown 格式,有了文本和图片等标签后,再进行对应部分的操作会更加方便。解析得到的 documents 可以直接用于构建 LlamaIndex 的向量索引,这是 RAG 系统的核心。
环境依赖
pip install llama-index-embeddings-openai llama-index-llms-openai
完整示例代码
from llama_index.core import VectorStoreIndex
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI # 导入OpenAI LLM类
from llama_index.core.settings import Settings
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# 设置为全局默认Embedding模型
Settings.embed_model = OpenAIEmbedding(
model="text-embedding-3-small",
api_key=os.getenv("OPENAI_API_KEY"),
api_base=os.getenv("OPENAI_BASE_URL", "https://api.openai.com/v1")
)
# 设置为全局默认 LLM
Settings.llm = OpenAI(
model="gpt-5-nano",
api_key=os.getenv("OPENAI_API_KEY"),
api_base=os.getenv("OPENAI_BASE_URL", "https://api.openai.com/v1")
)
# 解析pdf文档
documents = smart_load("甬兴证券-AI行业点评报告:海外科技巨头持续发力AI,龙头公司中报业绩亮眼.pdf")
# 构建索引
index = VectorStoreIndex.from_documents(documents)
# 生成查询引擎
query_engine = index.as_query_engine()
# 测试提问
response = query_engine.query("请用中文总结这些文档的主要内容")
print(response)