Corrective RAG(自我纠正的RAG)
本文介绍 Corrective RAG(自我纠正的 RAG)范式。
核心概念
Corrective RAG 是 RAG(检索增强生成)的改进范式,通过引入实时反馈与纠正机制,在生成过程中动态检测和修正错误,显著提升输出的准确性和可靠性。
核心思想:
- "生成-评估-纠正"闭环:在传统RAG的单次检索生成基础上,增加对生成内容的实时验证与迭代优化
- 多粒度纠错:从事实准确性、逻辑一致性、上下文连贯性等维度进行自我修正
与传统 RAG 的区别
| 特性 | 传统 RAG | Corrective RAG |
|---|---|---|
| 错误处理 | 依赖检索库质量,无主动纠错 | 动态检测并修正生成中的错误 |
| 生成流程 | 单向(检索→生成) | 循环(生成→评估→纠正→再生成) |
| 反馈信号 | 无或人工反馈 | 自动化验证(如事实核查、逻辑验证) |
| 输出可靠性 | 易受检索噪声或LLM幻觉影响 | 通过多次迭代降低错误率 |
核心思想
纠正性 RAG(Corrective RAG,简称CRAG)的核心思想是:先验证检索结果的可靠性,再决定是否使用或重新检索。
迭代式检索生成流程
流程说明:
- 用户问题首先进入智能体决策节点
- 智能体判断是否需要检索:
- 需要检索 → 进入检索+验证相关性节点
- 直接生成 → 进入生成答案节点
- 检索后评估结果是否可靠:
- 不可靠 → 重写查询,返回智能体决策重新判断
- 可靠 → 生成最终答案
实现要点
结果评估机制
def evaluate_retrieval(results):
"""评估检索结果的质量"""
if not results:
return False, "检索结果为空"
# 检查相似度分数
scores = [r.score for r in results]
if min(scores) < threshold:
return False, "相似度分数过低"
# 检查内容相关性
for doc in results:
if not is_relevant(doc, query):
return False, "内容不相关"
return True, "检索结果可靠"
查询重写策略
def rewrite_query(query, feedback):
"""根据反馈重写查询"""
prompt = f"""
原始查询: {query}
反馈信息: {feedback}
请重写查询,使其更准确地表达用户意图。
"""
return llm.invoke(prompt)
自我纠错循环
def corrective_rag(query, max_iterations=3):
"""带自我纠错的 RAG"""
for i in range(max_iterations):
# 1. 检索
results = retriever.invoke(query)
# 2. 评估
is_valid, feedback = evaluate_retrieval(results)
if is_valid:
# 3. 生成
return generate_answer(query, results)
# 4. 纠错 - 重写查询
query = rewrite_query(query, feedback)
# 超过最大迭代次数,返回兜底答案
return generate_answer(query, results)
代码实现
本节介绍基于 LangGraph 实现的 Agentic RAG 工作流,能够智能判断用户问题是否需要调用检索工具,并根据检索结果的相关性决定是生成答案还是重写问题。
流程图
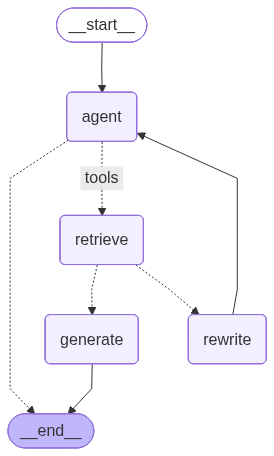
工作流程
-
agent 节点: LLM 根据问题决定是否调用检索工具
- 如果需要检索 → 进入
retrieve节点 - 如果可以直接回答 → 直接返回答案(END)
- 如果需要检索 → 进入
-
retrieve 节点: 执行检索工具,获取知识库中的相关文档
-
retrieve 后的条件边(grade_documents 函数): 评估检索到的文档是否与问题相关
- 相关 → 进入
generate节点 - 不相关 → 进入
rewrite节点
- 相关 → 进入
-
rewrite 节点: 重写问题,使其更易于检索到相关内容
- 重写后返回
agent节点重新决策
- 重写后返回
-
generate 节点: 基于检索到的上下文生成最终答案
核心代码
1. 状态定义 (graph_state1.py)
from typing import TypedDict, Annotated, Sequence
from langchain_core.messages import BaseMessage
from langgraph.graph import add_messages
from pydantic import BaseModel, Field
class Grade(BaseModel):
"""
相关性检查的二元评分
"""
binary_score: str = Field(description='相关性评分 "yes" or "no"')
class AgentState(TypedDict):
# add_messages 函数定义了应如何处理状态更新
# 所有消息都是继承 BaseMessage 的
messages: Annotated[Sequence[BaseMessage], add_messages]
要点:
AgentState是图的全局状态,包含消息列表add_messages是 LangGraph 提供的 annotator,自动处理消息追加Grade是用于文档相关性评分的 Pydantic 模型
2. Agent 节点 (agent_node.py)
from graph.graph_state1 import AgentState
from llm_models.all_llm_model import llm
from tools.retriever_tools import retriever_tool
from utils.log_utils import log
def agent_node(state: AgentState):
"""
调用智能体模型基于当前状态生成响应。根据问题,
它会决定使用检索工具检索,或者直接结束。
"""
log.info("---开始进入工作流---")
messages = state["messages"]
model = llm.bind_tools([retriever_tool])
response = model.invoke([messages[-1]])
return {"messages": [response]}
��要点:
llm.bind_tools([retriever_tool])让 LLM 决定是否调用工具- 传入
[messages[-1]]作为列表输入
3. 检索工具 (retriever_tools.py)
from langchain_core.tools import create_retriever_tool
from document.milvus_db import MilvusVectorSave
mv = MilvusVectorSave()
mv.create_connection()
retriever = mv.vector_store_saved.as_retriever(
search_type='similarity',
search_kwargs={
'k': 3,
'score_threshold': 0.1,
'ranker_type': 'rrf',
'ranker_params': {'k': 100},
'filter': {'category': 'content'}
}
)
retriever_tool = create_retriever_tool(
retriever,
'rag_retriever',
'搜索并返回关于 "半导体和芯片" 的信息'
)
要点:
- 使用
create_retriever_tool创建检索工具 - 工具名称为
retriever_tool
4. 条件路由函数 - 文档相关性评估 (grade_documents)
from typing import Literal
from langchain_core.prompts import PromptTemplate
from graph.get_human_message import get_last_human_message
from graph.graph_state1 import AgentState, Grade
from llm_models.all_llm_model import llm
def grade_documents(state) -> Literal["generate", "rewrite"]:
"""
判断检索到的文档是否与问题相关。
"""
log.info("---检查document的相关性---")
llm_with_structured = llm.with_structured_output(Grade)
prompt = PromptTemplate(
template="""你是一个评估检索文档与用户问题相关性的评分器。
这是检索到的文档: {context}
这是用户的问题:{question}
如果文档包含与用户问题相关的关键词或语义含义,则评为相关。
给出二元评分 'yes' 或 'no'。""",
input_variables=["context", "question"],
)
chain = prompt | llm_with_structured
messages = state["messages"]
last_message = messages[-1]
question = get_last_human_message(messages).content
docs = last_message.content
scored_result = chain.invoke({"question": question, "context": docs})
score = scored_result.binary_score
if score == "yes":
print("---输出:文档相关---")
return "generate"
else:
print("---输出:文档不相关---")
return "rewrite"
要点:
- 这是一个条件边路由函数,不是独立节点
- 通过
add_conditional_edges('retrieve', grade_documents, {...})注册到图 - 使用
llm.with_structured_output(Grade)获取结构化输出 - 返回
generate或rewrite决定下一步路由
5. 问题重写 (rewrite_node.py)
from langchain_core.messages import HumanMessage
from graph.get_human_message import get_last_human_message
from graph.graph_state1 import AgentState
from llm_models.all_llm_model import llm
def rewrite(state):
"""
转换查询以生成更好的问题。
"""
log.info("---转换查询---")
messages = state["messages"]
question = get_last_human_message(messages).content
msg = [
HumanMessage(
content=f"""分析输入并尝试理解潜在的语义意图/含义。
这是初始问题: {question}
请提出一个改进后的问题: """
)
]
response = llm.invoke(msg)
return {"messages": [response]}
6. 答案生成 (generate_node.py)
from langchain_core.messages import AIMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from graph.get_human_message import get_last_human_message
from graph.graph_state1 import AgentState
from llm_models.all_llm_model import llm
def generate(state):
"""
生成答案
"""
log.info("---生成最终的答案---")
messages = state["messages"]
question = get_last_human_message(messages).content
last_message = messages[-1]
docs = last_message.content
prompt = PromptTemplate(
template="你是一个问答任务助手。请根据以下检索到的上下文内容回答问题。如果不知道答案,请直接说明。\n问题:{question} \n上下文:{context} \n回答:",
input_variables=["question", "context"],
)
rag_chain = prompt | llm | StrOutputParser()
response = rag_chain.invoke({"context": docs, "question": question})
ai_message = AIMessage(content=response)
return {"messages": [ai_message]}
7. 工作流定义 (graph1.py)
from langgraph.checkpoint.memory import MemorySaver
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langgraph.prebuilt import ToolNode, tools_condition
from graph.agent_node import agent_node
from graph.generate_node import generate
from graph.graph_state1 import AgentState
from graph.rewrite_node import rewrite
from tools.retriever_tools import retriever_tool
# 定义一个新的工作流图
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node('agent', agent_node)
workflow.add_node('retrieve', ToolNode([retriever_tool]))
workflow.add_node('rewrite', rewrite)
workflow.add_node('generate', generate)
# 定义边
workflow.add_edge(START, 'agent')
# 条件边:agent 决定是否调用工具
workflow.add_conditional_edges('agent', tools_condition, {
'tools': 'retrieve',
END: END
})
# 条件边:检索后决定是否生成答案
workflow.add_conditional_edges(
'retrieve',
grade_documents,
{
'generate': 'generate',
'rewrite': 'rewrite'
}
)
workflow.add_edge('generate', END)
workflow.add_edge('rewrite', 'agent')
# 编译图状态
memory = MemorySaver()
graph = workflow.compile(checkpointer=memory)
要点:
StateGraph(AgentState)创建状态图add_node添加节点add_edge添加普通边add_conditional_edges添加条件边tools_condition根据 AI 消息是否有 tool_calls 决定路由MemorySaver提供状态持久化
8. 使用示例
from graph.graph1 import graph
import uuid
session_id = str(uuid.uuid4())
config = {'configurable': {'thread_id': session_id}}
inputs = {'messages': [('user', 'EUV光刻机是什么?')]}
events = graph.stream(inputs, config=config, stream_mode='values')
for event in events:
print(event)
适用场景
| 场景 | 说明 |
|---|---|
| 高准确性要求 | 医疗、法律、金融等领域 |
| 检索质量不稳定 | 知识库内容参差不齐 |
| 复杂多义查询 | 容易产生误导性检索结果 |
| 幻觉问题严重 | LLM 容易产生错误信息 |
总结
Corrective RAG 通过引入"生成-评估-纠正"闭环,显著提升了 RAG 系统的可靠性:
- 先验证后使用:不盲目信任检索结果
- 迭代优化:通过多轮迭代提升质量
- 动态调整:根据反馈动态调整检索策略