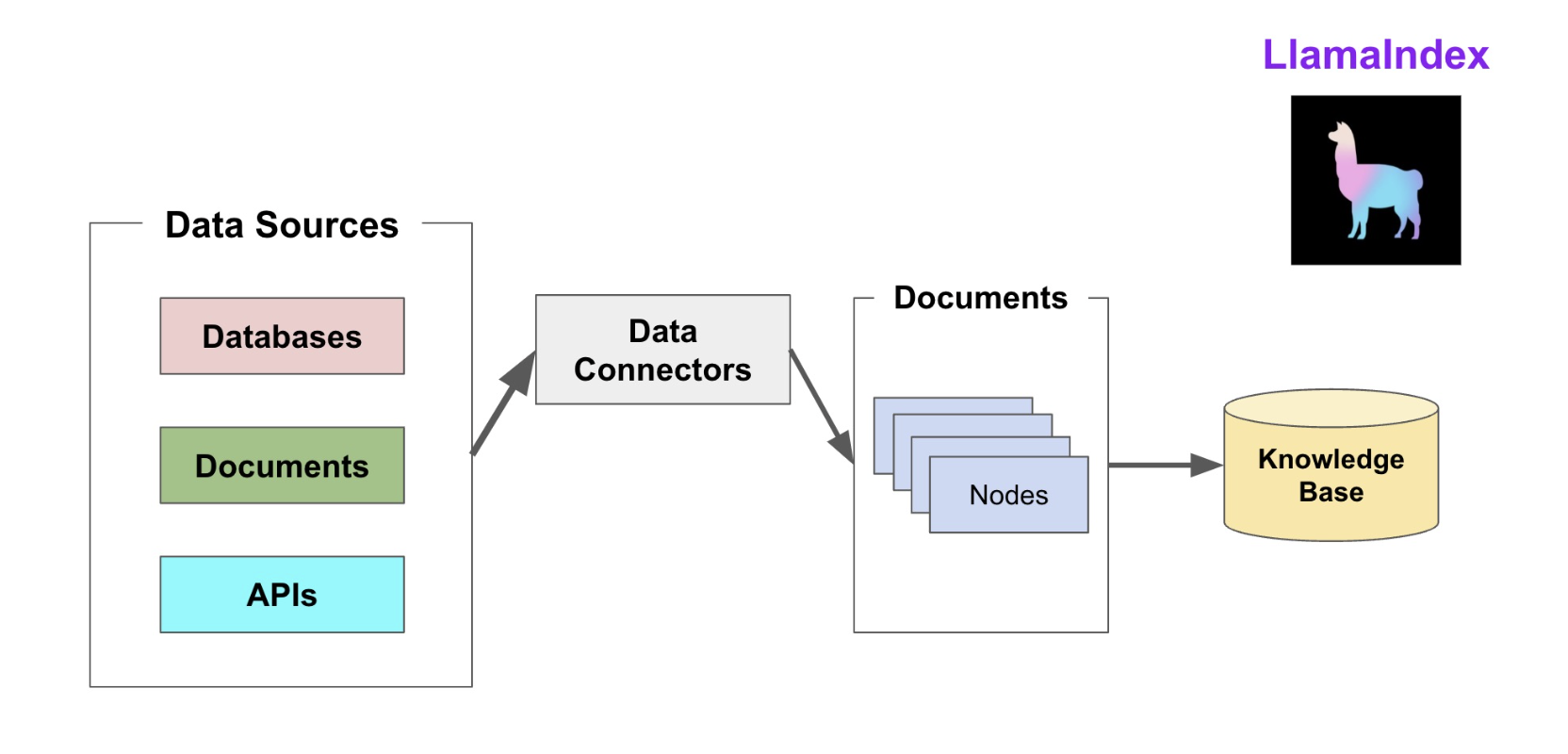
LlamaIndex 核心对象:Document 与 Node
LlamaIndex 将外部数据首先读取为 Document 对象,再通过 NodeParser 拆解为 Node 语义片段,以支持高效的索引构建与检索。
Document 与 Node 概念
| 维度 | Document(文档) | Node(节点) |
|---|---|---|
| 概念层级 | 顶层数据容器,代表一个完整的数据源 | 基础数据单元,由 Document 解析/分块而成 |
| 核心职责 | 数据的统一与标准化 | 数据的精细化组织与关联 |
| 内容与关系 | 包含完整的原始数据;Document 之间通常独立 | 包含数据片段;Node 之间可构建复杂的图结构 |
| 典型场景 | 数据加载与初始化,统一元数据管理 | 构建索引、语义检索,构建关系知识图谱 |
Document
- 数据的起点:任何外部数据(PDF、数据库、网页等)首先通过数据连接器加载为
Document对象,充当原始数据的统一接口。随后通过 NodeParser 将 Document 解析为多个 Node。 - 元数据承载:
Document级别适合存储文档整体的元数据(如file_name、author、category),这些元数据可被所有子 Node 继承。
Node
- 索引的基石:
Node是 LlamaIndex 构建索引的真正原材料,Document 到 Node 的切分过程对检索性能至关重要。 - 灵活的关系定义:每个
Node可与其他 Node 建立Next、Previous、Parent、Child等关系,支持构建树状或图状的知识结构,适用于长文档逻辑理解和多步推理。
核心要点
Document(数据容器) 负责承载原始数据,Node(语义单元) 作为构建索引、语义检索和生成回答的真正基石。理解两者的分工与协作,是有效使用 LlamaIndex 的关键。
元数据传播机制
LlamaIndex 中的元数据传播遵循以下继承原则:
- Document 级元数据:自动传播到所有由该 Document 生成的 Node
- Node 级元数据:可以覆盖或补充 Document 级元数据
- 关系元数据:存储 Node 之间的关系信息,如父子、前后关系
from llama_index.core import Document
# 导入句子分割器
from llama_index.core.node_parser import SentenceSplitter
# 创建 Document 并设置元数据
doc = Document(
text="这是一份��关于RAG技术的文档...",
metadata={
"file_name": "rag_guide.pdf",
"category": "技术文档",
"author": "AI研究团队",
"created_date": "2023-11-15"
}
)
# 从 Document 创建 Node 时,元数据会自动传播
splitter = SentenceSplitter()
nodes = splitter.get_nodes_from_documents([doc])
# 每个 Node 都会继承 Document 的 metadata
nodes[0].metadata
Node 结构
LlamaIndex 中,切分后的基本单元是 Node,每个 Node 包含以下核心属性:
| 属性名 | 类型 | 说明 |
|---|---|---|
| id_ (node_id) | str | 节点唯一标识符,可自动生成或手动指定 |
| text | str | 节点包含的文本内容(chunk) |
| metadata | Dict[str, Any] | 元数据信息(如文件名、页码等) |
| embedding | List[float] | 节点的向量嵌入表示 |
| relationships | Dict[NodeRelationship, RelatedNodeInfo] | 节点间关系映射 |
| hash | str | 内容哈希值,用于去重和变更检测 |
| excluded_embed_metadata_keys | List[str] | embedding 时排除的元数据键 |
| excluded_llm_metadata_keys | List[str] | LLM 处理时排除的元数据键 |
| start_char_idx | Optional[int] | 在原始文档中的起始字符位置 |
| end_char_idx | Optional[int] | 在原始文档中的结束字符位置 |
| text_template | str | 文本格式化模板 |
| metadata_template | str | 元数据格式化模板 |
from llama_index.core.schema import TextNode
# 创建 Node 的基本结构
node = TextNode(
text="这是切分后的文本内容", # 文本内容
metadata={ # 元数据
"file_name": "document.pdf",
"page_number": 1,
"chunk_id": 0
},
id_="node_id_123", # 唯一标识符
embeddings=[] # 文本嵌入向量(可选)
)
关系结构
切分后的 Node 之间可以建立多种关系:
- 前后关系:表示 Node 在原文档中的顺序
- 父子关系:表示层次化切分中的层级关系
- 相似关系:表示语义相似的 Node
"""
LlamaIndex NodeRelationship 关系类型详解
在 LlamaIndex 中,Node(节点) 是文档切分后的最小单位。
每个 Node 可以通过 relationships 建立与其他 Node �的关联,形成结构化的知识图谱。
把 Node 想象成一本书的组成:
- 页面(Page)= Node
- 书的目录(TOC)= 节点关系
节点关系就像是一本书的不同"导航方式":
1. 顺序导航(翻页):NEXT / PREVIOUS
2. 层级导航(目录):PARENT / CHILD
3. 来源追溯(版权页):SOURCE
"""
from llama_index.core.schema import TextNode, NodeRelationship
# =============================================================================
# 一、基础概念:什么是 NodeRelationship?
# =============================================================================
# NodeRelationship 是枚举类型,定义了节点之间可能的连接方式:
#
# - SOURCE :来源关系(这篇文档来自哪里?如 PDF 文件名)
# - NEXT :下一页(线性阅读顺序)
# - PREVIOUS :上一页(线性阅读顺序)
# - PARENT :父节点(包含当前节点的更大单元)
# - CHILD :子节点(当前节点包含的更小单元)
#
# =============================================================================
# 二、创建基础节点
# =============================================================================
# 模拟一个 PDF 文档被切分成 3 个块(chunk)
node0 = TextNode(
text="文档的引言部分:本文介绍 LlamaIndex 的使用方法...",
metadata={"file_name": "document.pdf", "chunk_id": 0},
id_="node_id_0"
)
node1 = TextNode(
text="文档的核心内容:如何构建索引和查询向量数据库...",
metadata={"file_name": "document.pdf", "chunk_id": 1},
id_="node_id_1"
)
node2 = TextNode(
text="文档的总结部分:本文总结了 LlamaIndex 的主要功能...",
metadata={"file_name": "document.pdf", "chunk_id": 2},
id_="node_id_2"
)
# =============================================================================
# 三、顺序关系(Sequential Relationship)
# =============================================================================
# 适用场景:模拟线性阅读顺序,如翻书页
#
# 关系图示:
# [node0] ---NEXT---> [node1] ---NEXT---> [node2]
# [node2] <-PREVIOUS-- [node1] <-PREVIOUS-- [node0]
# node1 的前面是 node0,后面是 node2
node1.relationships[NodeRelationship.SOURCE] = node0.id_
node1.relationships[NodeRelationship.NEXT] = node2.id_
node2.relationships[NodeRelationship.PREVIOUS] = node1.id_
# =============================================================================
# 四、层级关系(Hierarchical Relationship)
# =============================================================================
# 适用场景:模拟书籍的章节结构
#
# 关系图示:
# [node0: 章节] <--- PARENT
# |
# +--- [node1: 段落] <--- CHILD
# |
# +--- [node2: 段落] <--- CHILD
# node2 的父节点是 node0(层级包含关系)
node2.relationships[NodeRelationship.SOURCE] = node0.id_
# node1 是 node2 的父节点(node1 包含 node2)
node1.relationships[NodeRelationship.CHILD] = node2.id_
node2.relationships[NodeRelationship.PARENT] = node1.id_
# =============================================================================
# 五、打印节点关系,查看效果
# =============================================================================
print("=" * 60)
print("node1 的所有关系:")
print(node1.relationships)
print()
print("node2 的所有关系:")
print(node2.relationships)
print()
# =============================================================================
# 六、更完整的示例:模拟一本书的完整结构
# =============================================================================
print("=" * 60)
print("完整示例:一本书的节点关系结构")
print("=" * 60)
# 创建一本书的节点层次
# 层级结构:
# 章节1 (Chapter 1)
# ├── 段落1.1 (Paragraph)
# │ └── 句子1.1.1 (Sentence)
# └── 段落1.2 (Paragraph)
chapter1 = TextNode(
text="第一章:LlamaIndex 入门",
metadata={"type": "chapter", "level": 1},
id_="chapter_1"
)
para1_1 = TextNode(
text="1.1 什么是 LlamaIndex?它是一个强大的索引框架...",
metadata={"type": "paragraph", "parent_chapter": "chapter_1"},
id_="para_1_1"
)
para1_2 = TextNode(
text="1.2 为什么使用 LlamaIndex?它简化了 RAG 流程...",
metadata={"type": "paragraph", "parent_chapter": "chapter_1"},
id_="para_1_2"
)
sentence1_1_1 = TextNode(
text="LlamaIndex 的核心概念是索引(Index)和节点(Node)。",
metadata={"type": "sentence", "parent_paragraph": "para_1_1"},
id_="sentence_1_1_1"
)
# 建立层级关系
# 章节 包含 段落
chapter1.relationships[NodeRelationship.CHILD] = para1_1.id_
para1_1.relationships[NodeRelationship.PARENT] = chapter1.id_
# 段落 包含 句子
para1_1.relationships[NodeRelationship.CHILD] = sentence1_1_1.id_
sentence1_1_1.relationships[NodeRelationship.PARENT] = para1_1.id_
# 段落之间的顺序关系
para1_1.relationships[NodeRelationship.NEXT] = para1_2.id_
para1_2.relationships[NodeRelationship.PREVIOUS] = para1_1.id_
# 所有节点都标注来源书籍
for node in [chapter1, para1_1, para1_2, sentence1_1_1]:
node.relationships[NodeRelationship.SOURCE] = "《LlamaIndex 实战指南》"
# 打印层级关系
print("\n【章节 -> 段落 -> 句子】的层级关系:")
print(f"章节 (Chapter): {chapter1.text}")
print(f" ├── 段落 (Paragraph): {para1_1.text}")
print(f" │ └── 句子 (Sentence): {sentence1_1_1.text}")
print(f" └── 段落 (Paragraph): {para1_2.text}")
print("\n【查询某个句子的完整路径】:")
print(f"句子内容: {sentence1_1_1.text}")
print(f"父段落: {sentence1_1_1.relationships.get(NodeRelationship.PARENT)}")
print(f"段落父章节: {para1_1.relationships.get(NodeRelationship.PARENT)}")
print(f"来源书籍: {sentence1_1_1.relationships.get(NodeRelationship.SOURCE)}")
# =============================================================================
# 七、关系类型使用建议
# =============================================================================
print("\n" + "=" * 60)
print("NodeRelationship 使用建议")
print("=" * 60)
print("""
| 关系类型 | 适用场景 | 示例 |
|----------------|-------------------------------|-------------------------------|
| SOURCE | 追溯文档来源 | PDF 文件名、网页 URL |
| NEXT/PREVIOUS | 线性阅读顺序、上下文连续性 | 文章的上一段/下一段 |
| PARENT/CHILD | 结构化层次、包含关系 | 章节-段落、段落-句子 |
""")
# =============================================================================
# 八、实际应用:RAG 中的节点关系
# =============================================================================
print("\n" + "=" * 60)
print("实际应用:RAG 检索中使用节点关系")
print("=" * 60)
print("""
在 RAG(检索增强生成)场景中,节点关系可以帮助:
1. 【上下文补全】当检索到 node1 时,可通过 NEXT/PREVIOUS
获取前后文,补充完整语境
2. 【层级摘要】当检索到叶子节点(句子)时,可通过 PARENT
向上追溯,获取更高层次的摘要信息
3. 【来源追踪】通过 SOURCE 关系,标注检索结果来自哪篇文档,
增强答案的可信度
4. 【去重过滤】利用节点关系,避免返回重复或冗余的检索结果
""")
print("\n节点关系设置完成!")
注意
关系的建立需要手动指定,但使用内置的 NodeParser(如 SentenceSplitter、HierarchicalNodeParser)时会自动建立 PREVIOUS/NEXT 和 PARENT/CHILD 关系。
关系类型说明
| 关系类型 | 值 | 含义 | 使用场景 |
|---|---|---|---|
| SOURCE | 1 | 指向源文档的引用 | 每个 Node 追溯原始 Document |
| PREVIOUS | 2 | 前一个兄弟节点 | 保持文档顺序,支持 Sentence Window Retrieval |
| NEXT | 3 | 下一个兄弟节点 | 与 PREVIOUS 构成双向链表,支持前后文��扩展检索 |
| PARENT | 4 | 层级结构中的父节点 | HierarchicalNodeParser 核心机制,支持多层级切分 |
| CHILD | 5 | 子节点集合 | 父节点维护对所有子节点的引用,值可为 List[RelatedNodeInfo] |