Text-Splitters 文本分割器
Text-Splitters 专注于将任意文本字符串拆分成多个片段,按字符、句子、token 或自定义分隔规则进行切分,通常只关心文本长度与重叠上下文,不涉及文件格式的解析。
TextSplitter 与 NodeParser 对比
在 LlamaIndex 中,TextSplitter 和 NodeParser 是两类不同层级的切分工具,选型时需要根据业务复杂度做出取舍。
| 维度 | TextSplitter | NodeParser |
|---|---|---|
| 核心定位 | 基础文本分割工具 | 高级文档解析与节点生成框架 |
| 处理逻辑 | 基于固定规则(长度、标点、字符递归分割) | 可集成语义分割、代码解析等复杂策略 |
| 输出结果 | 文本块(字符串列表) | Node 对象列表(含文本、元数据、节点关系) |
| 语义感知 | 通常不具备 | 部分解析器(如 SemanticSplitterNodeParser)具备 |
| 性能特点 | 轻量快速,计算开销小 | 功能更强但可能较慢 |
| 适用场景 | 简单文本处理、快速原型 | 生产级 RAG 系统、复杂文档处理 |
TokenTextSplitter
TokenTextSplitter 按照 token 长度进行切分,适用于需要精确控制 token 数量的场景,特别是在有严格 token 限制的嵌入模型或语言模型中使用。
核心特性:
- 基于 token 切分:以 token 而非字符为单位,更准确地反映模型的处理能力
- 支持多种 tokenizer:兼容 tiktoken、HuggingFace tokenizer 等不同的 token 计算方法
- 多语言适配:不同语言的 token 密度差异大(如中文一个字可能对应多个 token),按 token 切分更精准
from llama_index.core.node_parser import TokenTextSplitter
from llama_index.core import Document # 文档对象,用于 get_nodes_from_documents 方法
# ============================================
# TokenTextSplitter: 基于 token 数量的文本分块器
# ============================================
# 初始化 TokenTextSplitter
token_splitter = TokenTextSplitter(
chunk_size=512, # 每 chunk 目标 token 数(可调)
chunk_overlap=64, # 重叠 token 数(可调)
separator=" " # 分隔符(一般用空格)
)
# ============================================
# get_nodes_from_documents vs split_text 的区别
# ============================================
# - split_text: 直接对文本字符串进行分块,返回 List[str]
# - get_nodes_from_documents: 接收 Document 对象列表,返回 List[Node]
# Node 对象包含更多元信息(如文档ID、关系等),适合完整的 RAG 流程
#
# 注释掉的代码示意(需要先创建 Document 对象):
# documents = [Document(text=test_text)]
# nodes_from_tokens = token_splitter.get_nodes_from_documents(documents)
# print(nodes_from_tokens[1].get_content()) # Node 对象使用 get_content() 获取文本
# 测试文本
test_text = """在检索增强生成(RAG)系统中,文档切分与 Node 转换作为连接原始数据与语言模型的关键预处理环节,直接决定了系统的检索精度、生成质量及整体性能。行业实践数据表明,90% 的 RAG 效果问题源于元数据与分块策略不当,而通过优化分块策略可使检索准确率提升 30 - 50%,语义分块较固定�分块的准确率优势可达 27%。这一技术环节的重要性体现在:分块过大易引入冗余噪音,增加语言模型理解负担;分块过小或切分不当则可能破坏语义连贯性,导致完整知识点被拆分;未能适配文档结构的机械分块方式还会忽视标题、列表等结构化信息,影响信息提取完整性。
LlamaIndex 作为连接自定义数据与大语言模型(LLMs)的核心框架,通过将文档(如 PDF、文本文件)分解为包含文本内容、向量嵌入和元数据的 Node 组件,构建了结构化文档管理的技术范式。其核心抽象在于将原始文档转换为语义连贯的 Node 集合,向量存储仅保留 Node 内容的嵌入向量与文本信息,这一机制简化了索引构建流程并提升了检索相关性。文档切分与 Node 转换的质量不仅影响向量检索的效率,更决定了上下文增强(Context Augmentation)这一 RAG 核心能力的实现效果。
本文聚焦文档切分与 Node 转换的技术实践,结合 LlamaIndex 框架的实现机制,系统调研分块策略设计、元数据管理及 Node 组件化等关键技术点。通过分析行业最佳实践与典型案例,旨在为 RAG 系统开发者提供可落地的优化方案,解决分块噪音、语义断裂、结构信息丢失等核心痛点,为构建高性能检索增强生成应用奠定技术基础。"""
# 按照文本来��进行切分
nodes_from_tokens = token_splitter.split_text(test_text)
# 打印切分后的文本数量
print( "切分后的文本数量: " + str(len(nodes_from_tokens)))
print("===============================================")
# 打印第一个文本
print("第一个文本:")
print(nodes_from_tokens[0])
print("===============================================")
# 打印第二个文本
print("第二个文本:")
print(nodes_from_tokens[1])
print("===============================================")
# ============================================
# 补充示例:使用 get_nodes_from_documents 方法
# ============================================
print("\n\n========== get_nodes_from_documents 示例 ==========\n")
# 创建 Document 对象(包含元数据)
documents = [Document(text=test_text, metadata={"source": "RAG技术文档", "author": "AI研究员"})]
# 使用 get_nodes_from_documents 转换为节点
nodes = token_splitter.get_nodes_from_documents(documents)
print(f"从 Document 转换得到的节点数量: {len(nodes)}")
print(f"\n第一个节点的文本内容:\n{nodes[0].get_content()[:200]}...")
print(f"\n第一个节点的元数据: {nodes[0].metadata}")
print(f"节点ID: {nodes[0].node_id}")
SentenceSplitter
SentenceSplitter 基于自然语言句子和段落边界进行分割,类似于 LangChain 的 RecursiveCharacterTextSplitter。它优先在句子结束处或段落分隔符处切分,尽量避免在句子中间切断,是 LlamaIndex 中最常用的默认文本分割器。

核心特性与工作原理:
- 保持句子完整性:首先尝试按句子边界(中文
。!?、英文.!?)进行分割 - 递归分割策略:若单个句子长度超过
chunk_size,递归使用更小的分隔符继续拆分 - 重叠控制:通过
chunk_overlap参数让相邻文本块之间保留少量重叠 token,保持上下文连贯 - 多语言支持:通过
separator参数可自定义分隔符,适配不同语言
关键参数:
| 参数名 | 类型 | 说明 | 默认值 |
|---|---|---|---|
chunk_size | int | 每个文本块的目标最��大 token 数 | 1024 |
chunk_overlap | int | 相邻文本块之间重叠的 token 数 | 200 |
separator | str | 用于分割的主要分隔符 | " " |
paragraph_separator | str | 用于识别段落的分隔符 | "\n\n\n" |
适用场景:SentenceSplitter 非常适用于自然语言文本,如新闻文章、博客文章、书籍章节等结构清晰的散文体内容。
from llama_index.core import Document
from llama_index.core.node_parser import SentenceSplitter
# ============================================
# SentenceSplitter: 基于句子层级的文本分块器
# ============================================
# 初始化 SentenceSplitter
# 与 TokenTextSplitter 的区别:SentenceSplitter 按自然句子切分,
# 而 TokenTextSplitter 按固定 token 数量切分
sentence_splitter = SentenceSplitter(
chunk_size=512, # 目标 chunk 大小(token 近似值)
chunk_overlap=64 # 相邻 chunk 之间的重叠 token 数
)
# ============================================
# 两种切分方式对比
# ============================================
# 1. split_text(text): 直接对字符串分块,返回 List[str]
# 2. get_nodes_from_documents(documents): 对 Document 对象列表分块,返回 List[Node]
#
# 注释掉的代码示意:
# nodes_from_sentences = sentence_splitter.get_nodes_from_documents(documents)
# print(nodes_from_sentences[0].get_content())
# 测试文本
test_text = """在检索增强生成(RAG)系统中,文档切分与 Node 转换作为连接原始数据与语言模型的关键预处理环节,直接决定了系统的检索精度、生成质量及整体性能。行业实践数据表明,90% 的 RAG 效果问题源于元数据与分块策略不当,而通过优化分块策略可使检索准确率提升 30 - 50%,语义分块较固定分块的准确率优势可达 27%。这一技术环节的重要性体现在:分块过大易引入冗余噪音,增加语言模型理解负担;分块过小或切分不当则可能破坏语义连贯性,导致完整知识点被拆分;未能适配文档结构的机械分块方式还会忽视标题、列表等结构化信息,影响信息提取完整性。
LlamaIndex 作为连接自定义数据与大语言模型(LLMs)的核心框架,通过将文档(如 PDF、文本文件)分解为包含文本内容、向量嵌入和元数据的 Node 组件,构建了结构化文档管理的技术范式。其核心抽象在于将原始文档转换为语义连贯的 Node 集合,向量存储仅保留 Node 内容的嵌入向量与文本信息,这一机制简化了索引构建流程并提升了检索相关性。文档切分与 Node 转换的质量不仅影响向量检索的效率,更决定了上下文增强(Context Augmentation)这一 RAG 核心能力的实现效果。
本文聚焦文档切分与 Node 转换的技术实践,结合 LlamaIndex 框架的实现机制,系统调研分块策略设计、元数据管理及 Node 组件化等关键技术点。通过分析行业最佳实践与典型案例,旨在为 RAG 系统开发者提供可落地的优化方案,解决分块噪音、语义断裂、结构信息丢失等核心痛点,为构建高性能检索增强生成应用奠定技术基础。"""
# ============================================
# 示例1:使用 split_text 方法(返回 List[str])
# ============================================
print("========== split_text 示例 ==========\n")
nodes_from_sentences = sentence_splitter.split_text(test_text)
print(f"切分后的文本数量: {len(nodes_from_sentences)}")
print("===============================================")
print("第一个文本:")
print(nodes_from_sentences[0])
print("===============================================")
print("第二个文本:")
print(nodes_from_sentences[1])
print("===============================================")
# ============================================
# 示例2:使用 get_nodes_from_documents 方法(返回 List[Node])
# ============================================
print("\n\n========== get_nodes_from_documents 示例 ==========\n")
documents = [Document(text=test_text, metadata={"source": "RAG技术文档", "author": "AI研究员"})]
nodes = sentence_splitter.get_nodes_from_documents(documents)
print(f"从 Document 转换得到的节点数量: {len(nodes)}")
print(f"\n第一个节点的文本内容:\n{nodes[0].get_content()[:200]}...")
print(f"\n第一个节点的元数据: {nodes[0].metadata}")
print(f"节点ID: {nodes[0].node_id}")
print(f"\n第二个节点的文本内容:\n{nodes[1].get_content()[:200]}...")
print(f"\n第二个节点的元数据: {nodes[1].metadata}")
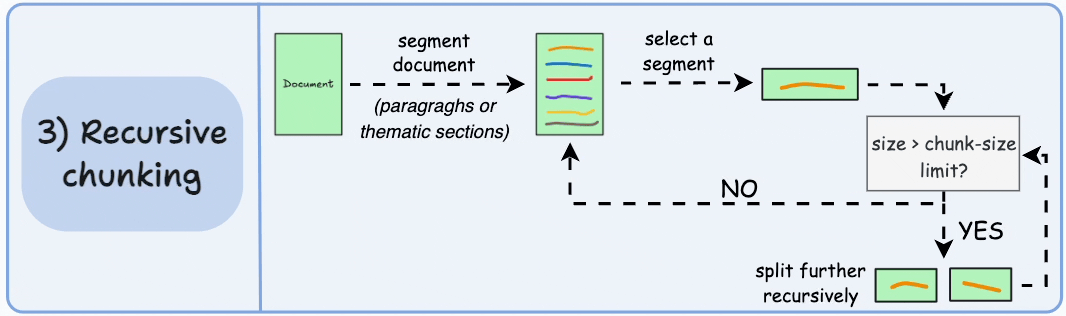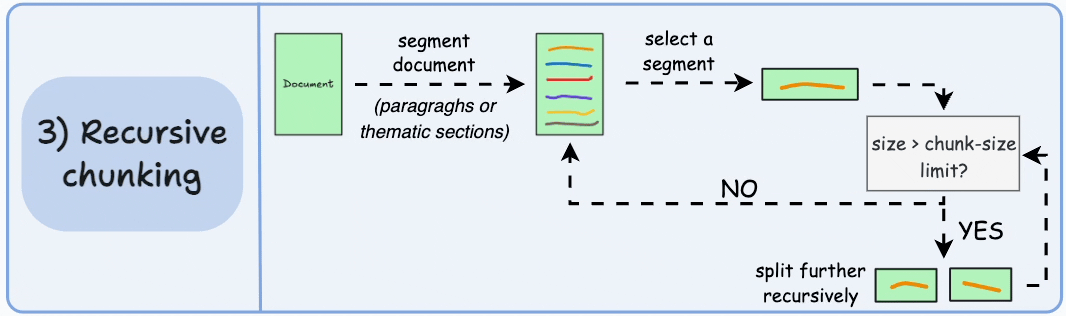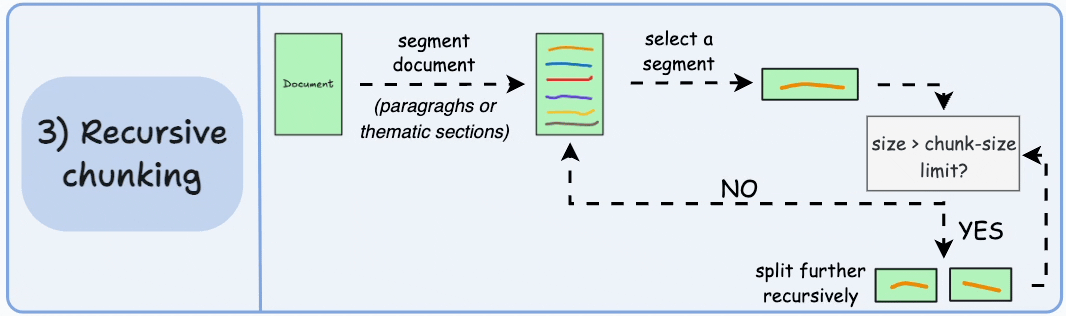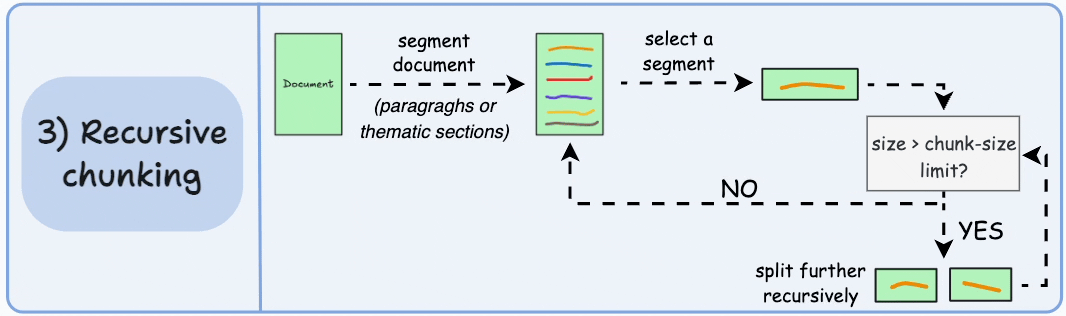
递归切分
当文本块超过预定义的 chunk_size 时,SentenceSplitter 会自动触发递归切分:
- 自动降级:如果分块大小超过限制,递归使用更小的分隔符(如逗号、空格)继续拆分,直到满足要求
- 保持自然流畅:与固定大小切分不同,递归切分保持了语言的自然流畅性,保留完整的思想
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.schema import Document
# 示例文本:一个长句子
text = "这是一个非常长的句子,它包含了多个逗号分隔的部分,和一些短的文本,因此整个句子的长度会很容易超过我们设定的块大小限制。短句。"
document = Document(text=text)
# 设定极小的块大小以触发递归分割
splitter = SentenceSplitter(
chunk_size=10,
chunk_overlap=0,
separator=",。!?!?.\n¡¿"
)
nodes = splitter.get_nodes_from_documents([document])
# 打印分割结果
for i, node in enumerate(nodes):
print(f"块 {i+1}: {node.text}")
# TextNode节点信息
{
'id_': '5c0c3c5f-614e-41fb-b26b-eec080d8096e',
'embedding': None,
'metadata': {},
'excluded_embed_metadata_keys': [],
'excluded_llm_metadata_keys': [],
'relationships': { < NodeRelationship.SOURCE: '1' > :RelatedNodeInfo(node_id = 'c21e5d07-d7d6-43ed-a54c-523ec7046359', node_type = <ObjectType.DOCUMENT: '4' > , metadata = {},
hash = '5941844fa9c40295c3fe1ee08abb5952ab4590d1951fb2150f644e3f19a18159'),
<NodeRelationship.NEXT: '3' > :RelatedNodeInfo(node_id = '7d757fbc-4f2a-48aa-852a-8be7692b0572', node_type = <ObjectType.TEXT: '1' > , metadata = {},
hash = 'e611f789a713d9540163feb55ff3c55fb0f80f43142631e1ce9c642ec49944ff')
},
'metadata_template': '{key}: {value}',
'metadata_separator': '\n',
'text': '这是一个非常长的句',
'mimetype': 'text/plain',
'start_char_idx': 0,
'end_char_idx': 9,
'metadata_seperator': '\n',
'text_template': '{metadata_str}\n\n{content}'
}
CodeSplitter
CodeSplitter 专为编程语言源代码设计,利用抽象语法树(AST)来理解代码结构,确保按功能单元进行分割。
核心特性:
- 基于 AST 的结构化解析:不是简单按行数切分,而是理解代码的语法结构(函数、类、方法等)
- 语言特定:需要通过
language参数指定编程语言,支持 Python、JavaScript、Java 等多种语言 - 保持功能完整性:确保函数、类等代码块不会在中间被切断
依赖安装
使用 CodeSplitter 前需安装 tree-sitter 相关依赖:
pip install tree_sitter tree_sitter_language_pack
from llama_index.core.node_parser import CodeSplitter
from llama_index.core.schema import Document
# 示例 Python 代码
sample_code = '''
def calculate_fibonacci(n):
"""计算斐波那契数列的第 n 项"""
if n <= 1:
return n
else:
return calculate_fibonacci(n-1) + calculate_fibonacci(n-2)
class MathOperations:
"""一个简单的数学操作类"""
def __init__(self):
self.version = "1.0"
def factorial(self, n):
"""计算阶乘"""
if n == 0:
return 1
result = 1
for i in range(1, n+1):
result *= i
return result
def is_prime(self, n):
"""判断是否为质数"""
if n < 2:
return False
for i in range(2, int(n**0.5)+1):
if n % i == 0:
return False
return True
'''
# 初始化 CodeSplitter,指定 Python 语言
code_splitter = CodeSplitter(
language="python", # 指定编程语言
chunk_lines=10, # 每块大约行数
chunk_lines_overlap=2, # 块之间重叠行数
max_chars=600 # 每块最大字符数
)
# 执行切分
nodes = code_splitter.split_text(sample_code)
print(f"原始代码字符数: {len(sample_code)}")
print(f"切分后的节点数量: {len(nodes)}")
# 显示切分结果
for i, node in enumerate(nodes):
print(f"\n节点 {i+1} (字符数: {len(node)}):")
print("-" * 30)
print(node)
注意事项
- CodeSplitter 依赖 tree-sitter 的语言解析器,首次使用某语言时需要下载对应的解析器
language参数值必须与 tree-sitter 支持的语言名称匹配(如"python"、"javascript"、"java")- 对于非常短的代码文件,切分结果可能只有一个节点