RAG 核心概念与应用场景
传统大模型的局限性
在大模型真正落地使用时会发现,通用大模型基本无法满足真实的业务场景需求,主要有以下几个原因:
-
知识可能过时(训练数据有时效性):每个大语言模型的训练数据都存在时效性,所有训练数据都是离线整理归纳完成的,模型训练完成发布后,之后发生的事情模型本身没有进行训练,也就无法回答这部分内容。
-
会产生"幻觉"(编造不存在的信息):大模型的"幻觉"是指模型生成的内容看似合理,但实际上与既定事实、真实数据或逻辑相违背,即"一本正经地胡说八道"。
-
无法访问私有知识库数据:大模型本身学习不到企业或者个人的私有知识库知识,也就无法回答这部分的内容。
-
回答缺乏具体出处,难以验证:有些调研搜索的业务场景下,需要大模型对回答的内容给出具体的出处,一般是文章、论文等资料,这样可以进一步核查模型回答内容的真实性。
-
最大对话上下文限制(大部分模型 128K):大部分的模型上下文限制还是 128K 左右,一次性最大 10 万个汉字,可以处理的上下文长度是有限的。
RAG 的核心概念
什么是 RAG?
RAG = Retrieval(检索) + Augmented(增强) + Generation(生成)
RAG 即检索增强生成,为 LLM 提供了从某些数据源检索到的信息,并基于此修正生成的答案。RAG 基本上是 Search + LLM 提示,可以通过大模型回答查询,并将搜索所找到的信息作为大模型的上下文。查询和检索到的上下文都会被注入到发送到 LLM 的提示语中。
想象一下"开卷考试":
- 传统 AI 模型:像"闭卷考试"——只能依靠模型本身记忆中的知识回答问题
- RAG 系统:像"开卷考试"——遇到回答不了的问题时,先去查阅资料(检索),然后结合用户的提问进行归纳整理(增强),最后 LLM 给出答案(生成)
一个简单完整的 RAG 系统如下图:用户进行了提问,提出的问题会先去知识库里进行检索答案,检索到相似度最高的前 N 个答案,然后和用户的提问一起放入到 Prompt 里,交给大语言模型,大语言模型根据用户的提问和给出检索的知识来进行整理总结,最终输出返回给用户结果。
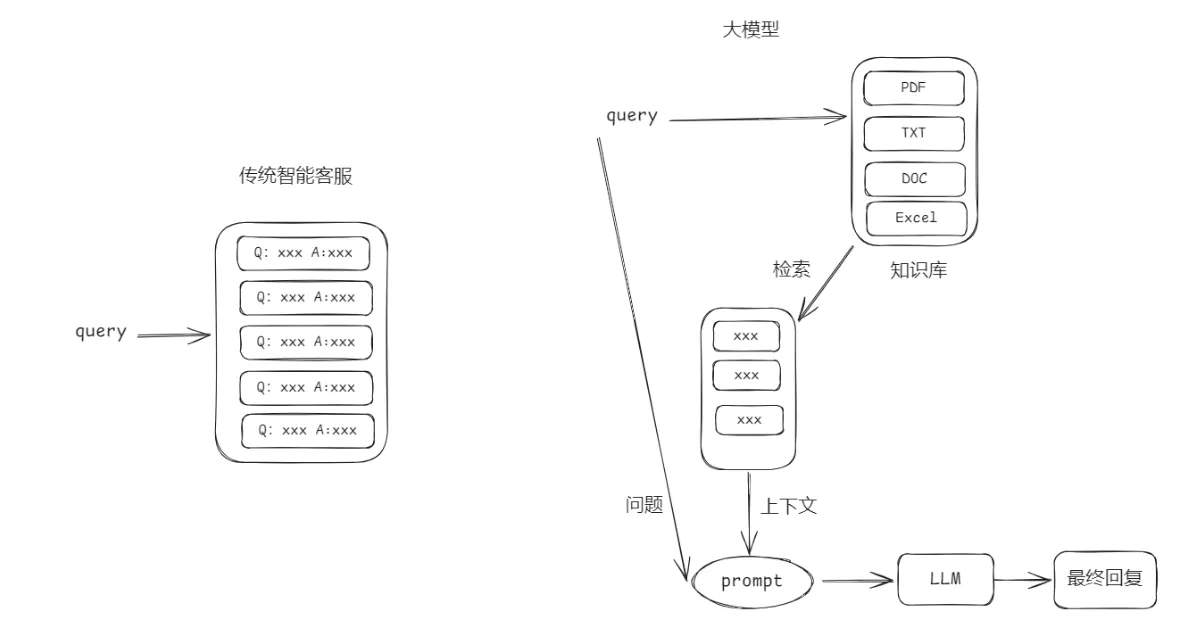
RAG 的本质
让大模型学会"查资料"后再回答问题,而不是仅凭记忆回答。
- 网络搜索资料
- 知识库存储资料
这样既保证了答案的准确性、时效性,又提供了可追溯的信息来源。
RAG 的优势
-
灵活性、适应性强:可以接入最新、不断变化的数据。RAG 的优势在于能够接入最新的、私有的、还有不断更新的数据,来作为大模型外接知识库,解决大模型回答问题的时效性问题。
-
提高准确性:回答有据可查,减少幻觉。基于知识库中检索到的知识来进行回答,回答的内容有据可查,也减少了模型的幻觉。
-
成本相对低:无需重新训练或微调模型,只需维护知识库。能够让大模型学会特定领域的知识灌入其实还有微调大模型这一方案,使用整理好的一定数量的数据集对 LLM 进行参数的调整,让大模型能够学习和理解我们自己的业务逻辑,有更好的 zero-shot 能力,但是需要算力成本,并且技术门槛比较高。
-
个性化程度高:特别适合专业领域知识问答。很多企业内部都在应用 RAG 技术,就是为了能够对接自己公司私有的知识数据,让用户能够直接对自己内部资料进行智能问答。
真实使��用案例
场景:咨询 2025 年最新的 AI 技术趋势
传统 AI 的回答
基于我 2024 年之前的训练数据,AI 技术趋势包括...(可能缺少 2025 年的最新信息)
RAG 系统的回答过程
- 检索到最新的行业报告、技术博客
- 找到与"2025 AI 趋势"最相关的段落
- 结合这些最新信息生成回答:
根据 2025 年最新的行业报告显示,当前主要趋势包括:
- 多模态大模型的发展...
- Agent 技术的普及... 【信息来源:XX 科技 2025 年度报告】
联网搜索功能的场景
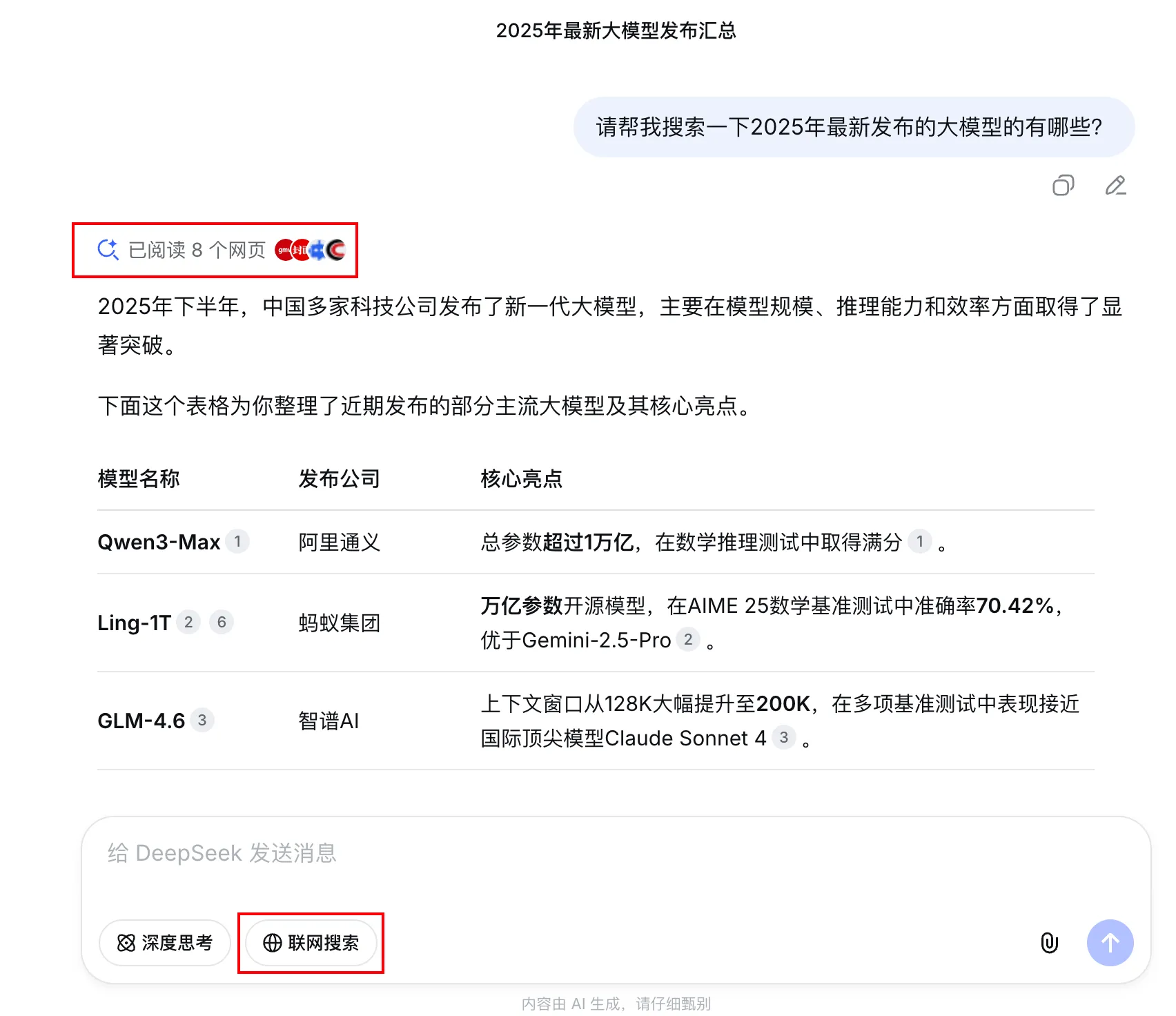
核心逻辑:预抓取与静态检索
-
当你使用 DeepSeek 时,它调用的并非你问题中提及的某个网站的实��时状态。DeepSeek 和其他大模型厂商一样,运行着庞大的网络爬虫系统,持续地从互联网上抓取海量网页内容,经过处理后存入其内部数据库。你得到的答案,正是模型基于这个数据库中的信息生成的。
-
由于依赖爬虫的周期性抓取,在不开启"联网搜索"时获得的信息可能存在延迟。正如此前一个测试发现,对于一个全新的或非常冷门的网站,不开启联网搜索,模型很可能无法获取其内容,或者只能找到数据库中近似的旧信息。
"联网搜索"功能的作用:
-
关闭时:模型仅从上述的静态数据库中检索信息。对于一些热门或存在已久的话题,数据库里很可能已有相关数据,因此它能直接给出带有引用的回答,让你感觉它"搜了网页"。
-
开启时:系统会额外发起一次实时的网络搜索,旨在获取尽可能最新的信息,以补充或验证静态数据库的内容。这对于查询新闻、实时股价等瞬息万变的信息至关重要。
企业 RAG 核心应用场景
企业知识库与智能问答
场景描述:
企业拥有大量内部文档(员工手册、产品文档、技术规范、会议纪要等),员工需要快速找到准确信息。
实际案例:
- 新员工入职培训问答(新员工培训成本高)
- 产品技术规格查询(文档分散在不同系统中)
- 公司政策咨询(搜索效率低,关键词匹配不精准)
专业客服与技术支持
场景描述:
为客户提供准确、一致的技术支持和问题解答。
RAG 优势:
- 基于最新产品文档和解决方案库(依赖客服人员的记忆)
- 提供标准化的准确回答(回答不一致,依赖个人经验)
- 减少培训时间,提高效率(处理复杂问题时响应慢)
科研与学术研究
场景描述:
研究人员需要快速了解某个领域的最新进展和相关文献。
价值体现:
- 快速文献调研
- 跨领域知识整合
- 研究趋势分析
还有其他的电商、法律、医疗、教育等等都是 RAG 应用的核心场景。