RAG 工作原理与完整执行流程
RAG 的工作原理
一个最基础的 RAG 技术实现流程如下图所示:
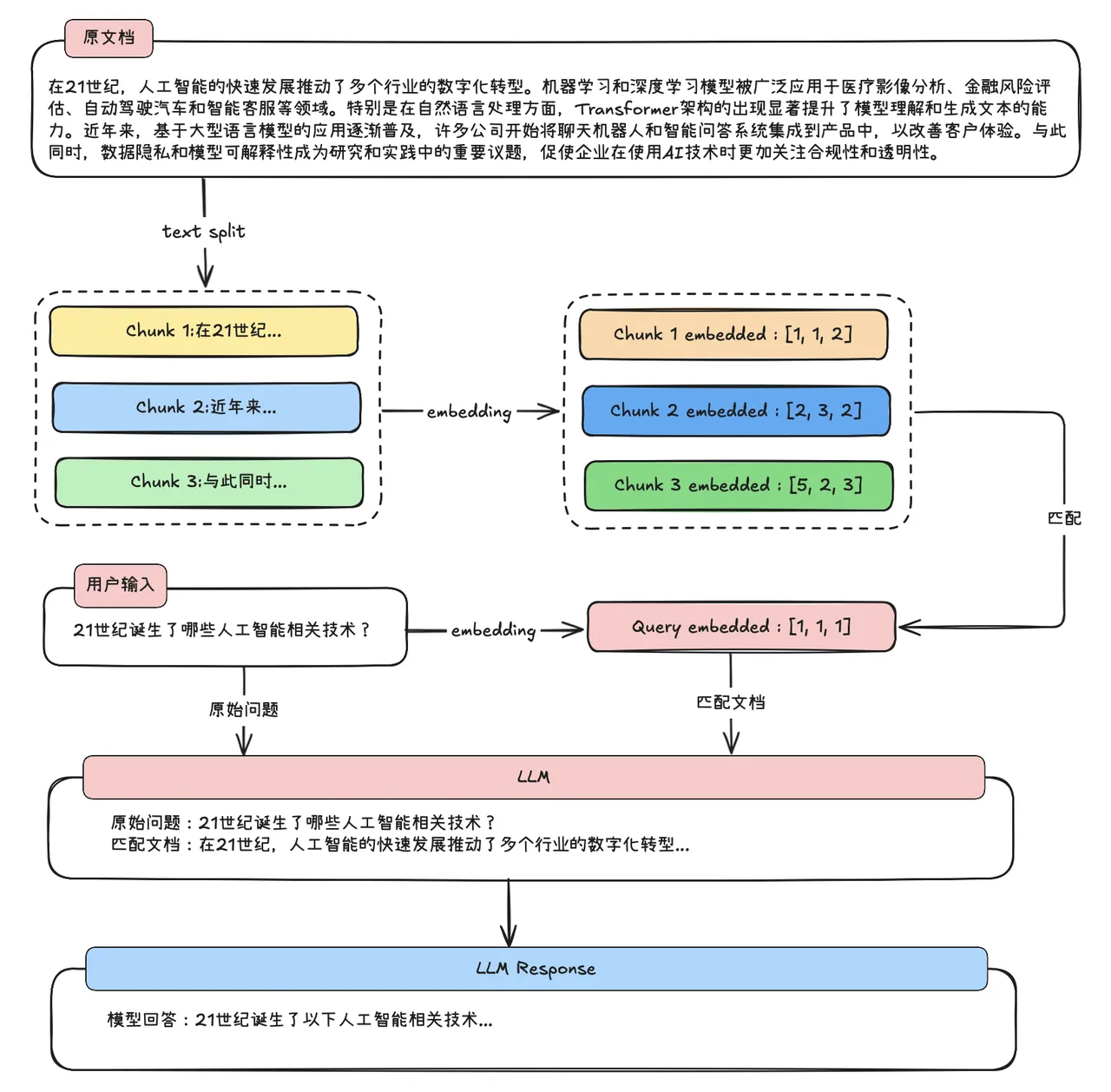
通用 RAG 基本工作流程(两阶段过程)
阶段一:准备阶段(建立知识库)
- 数据接入:收集各种文档(PDF、Word、网页等)
- 文档解析:提取文本内容
- 文档分割:将长文档切分成小片段
- 向量化:将文本转换为数学向量
- 存储:将向量存入专门的数据库
阶段二:问答阶段(智能应答)
- 用户提问:输入问题
- 问题向量化:将问题也转换成向量
- 相似度检索:在向量数据库中寻找最相关的文档片段
- 构建增强提示:将检索到的文档 + 原始问题组合成新的提示
- 生成答案:大语言模型基于增强后的提示生成最终答案
RAG 完整执行流程详解
知识库构建阶段(离线)
1. 数据源接入
目标:从各种来源收集原始数据
常见数据源:
- 本地文件(PDF、Word、TXT、Markdown)
- 数据库记录
- 网页内容
- API 接口数据
- 企业内部文档
# 示例:从多种数据源接入
data_sources = {
"本地文件": [".pdf", ".docx", ".txt"],
"网页内容": ["博�客", "文档", "新闻"],
"数据库": ["MySQL", "MongoDB"],
"API接口": ["企业知识库", "云存储"]
}
2. 文档解析
目标:从原始文件中提取纯文本内容
处理类型:
- PDF → 提取文字、表格
- HTML → 去除标签,保留正文
- Word → 解析文档结构
- 图片 → OCR 文字识别
技术工具:
- PyPDF2、pdfplumber(PDF 解析)
- BeautifulSoup(HTML 解析)
- python-docx(Word 解析)
- Tesseract(OCR)
安装 LangChain 依赖包(Python 版本最好是 3.10+):
pip install langchain langchain-openai langchain-community langchain-huggingface langchain-text-splitters docx2txt
使用 LangChain 进行 Word 文档解析示例:
# 使用 LangChain 进行 Word 文档解析示例
from langchain_community.document_loaders import Docx2txtLoader
# 初始化加载器,传入 Word 文档路径,加载文档为 Document 对象
loader = Docx2txtLoader("公司假期制度.docx")
documents = loader.load()
# 查看加载结果
print(f"加载了 {len(documents)} 个文档片段")
print(f"第一段内容预览: {documents[0].page_content[:200]}...")
print(f"元数据: {documents[0].metadata}")
输出示例:
加载了 1 个文档片段
第一段内容预览: 公司假期制度 1. 总则 1.1 本公司依据国家劳动法为员工提供病假、事假、年假、婚假、调休等假期...
元数据: {'source': '公司假期制度.docx'}
3. 文档分割
目标:将长文档切分成适合处理的知识片段(chunks)
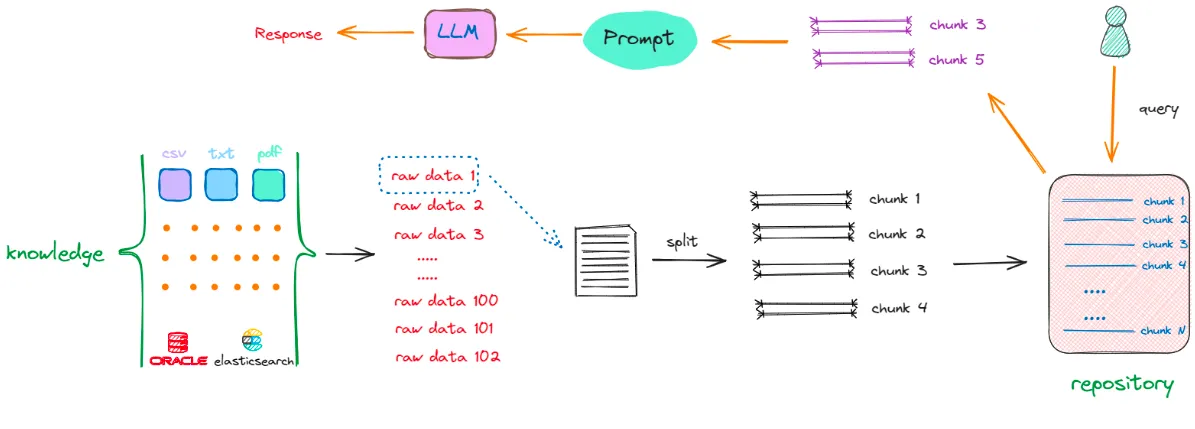
为什么需要分割?
- 大语言模型有输入长度限制
- 提高检索精度
- 避免信息过载
常用分割方法:
- 固定长度分割
- 按段落/句子分割
- 语义分割(按主题变化)
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 创建文本分割器,按照固定长度切分,并保留重叠部分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每个文本块的最大字符数
chunk_overlap=100, # 相邻文本块之间的重叠字符数(保持上下文连贯性)
separators=["\n\n", "\n", "。", "!", "?", ",", ""], # 定义了分割符的优先级顺序
add_start_index=True, # 记录每个块在原文档中的起始位置
)
# 执行分割
all_splits = text_splitter.split_documents(documents)
print(f"分割后得到 {len(all_splits)} 个文本块")
print(all_splits[0].page_content)
4. 词向量化
在数学中,向量(也称为欧几里得向量、几何向量),指具有大小(magnitude)和方向的量。它可以形象化地表示为带箭头的线段。箭头所指:代表向量的方向;线段长度:代表向量的大小。
例如,二维空间中的向量可以表示为 (x, y),表示从原点 (0,0) 到点 (x, y) 的有向线段。

- 将文本转成一组向量:每个下标
i,代表一个维度 - 整个数组对应一个
n维空间的一个点,即文本向量又叫 Embeddings - 向量之间可以计算距离,距离远近对应语义相似度大小
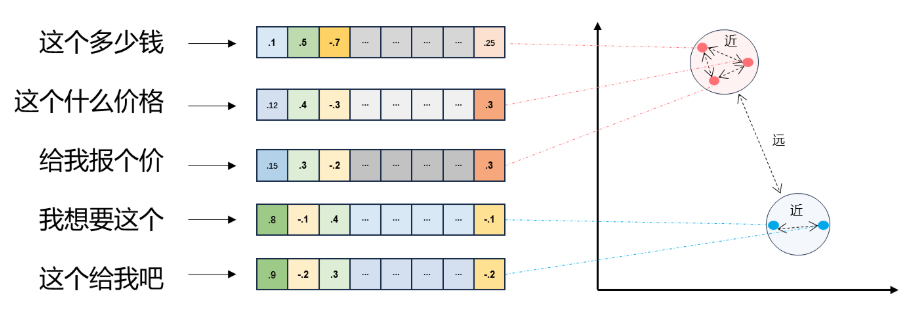
目标:将文本转换为数值向量(数学表示)
向量化原理:
文本:"RAG 技术很强大" ↓ 向量化模型(Embedding 模型) 向量:[0.12, -0.45, 0.78, ..., 0.33](384 维向量)
常用模型:
- OpenAI text-embedding-3
- 国产模型:M3E、BGE 等
安装依赖:
pip install openai sentence-transformers dotenv
使用 OpenAI 模型进行 Embedding 向量化:
# 加载 api_key 环境
from dotenv import load_dotenv
import os
# 加载环境变量
load_dotenv()
# OpenAI API 配置
OPENAI_API_KEY: str = os.getenv('OPENAI_API_KEY')
OPENAI_BASE_URL: str = os.getenv('OPENAI_BASE_URL')
# 默认模型配置
model_name = "text-embedding-3-small"
from openai import OpenAI
client = OpenAI(base_url=OPENAI_BASE_URL, api_key=OPENAI_API_KEY)
# 准备需要向量化的文本
text_to_embed = "今天天气真好,我们出去散步吧!"
# 调用 Embedding 模型
response = client.embeddings.create(
model=model_name, # 使用默认模型配置中的模型名称
input=text_to_embed # 需要向量化的文本
)
# 从响应中提取生成的向量
embedding_vector = response.data[0].embedding
print(f"生成向量的维度:{len(embedding_vector)}")
print(f"向量预览:{embedding_vector[:5]}...")
输出示例:
生成向量的维度:1536
向量预览:[0.03212086483836174, -0.002328116912394762, -0.025515884160995483, ...]...
使用国产模型进行 Embedding 向量化:
import os
# 设置 HuggingFace 镜像地址(国内加速)
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from langchain_huggingface import HuggingFaceEmbeddings
# 1. 初始化 BGE 嵌入模型
embeddings = HuggingFaceEmbeddings(
model_name='BAAI/bge-large-zh-v1.5',
model_kwargs={'device': 'cpu'} # 使用 GPU 可改为 'cuda'
)
# 2. 准备示例文本
text = "机器学习是人工智能的重要分支"
# 3. 执行向量化
vector = embeddings.embed_documents([text])[0]
# 4. 打印结果
print(f"文本: '{text}'")
print(f"向量维度: {len(vector)}")
print(f"向量值: {vector[:5]}...")
输出示例:
文本: '机器学习是人工智能的重要分支'
向量维度: 1024
向量值: [0.040067244321107864, 0.01246691681444645, ...]...
如果运行时遇到 ipywidgets 相关报错,只需要执行:pip install --upgrade ipywidgets
5. 文档存储
目标:将向量和原文存储到专用数据库中
向量数据库选择:
- ChromaDB(轻量级,易用)
- Pinecone(云服务,高性能)
- Faiss(高并发,GPU 加速)
- Milvus(毫秒级搜索万亿级向量数据)
安装依赖:
pip install faiss-cpu
# 有 CUDA 的可以安装 GPU 版本:pip install faiss-gpu
import os
# 设置 HuggingFace 镜像地址(国内加速)
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from langchain_community.vectorstores import FAISS
from langchain_huggingface import HuggingFaceEmbeddings
# 初始化嵌入模型
embeddings = HuggingFaceEmbeddings(
model_name='BAAI/bge-large-zh-v1.5',
model_kwargs={'device': 'cpu'} # 使用 GPU 可改为 'cuda'
)
# 创建向量数据库
vectorstore = FAISS.from_documents(all_splits, embeddings)
# 保存到本地(可选)
vectorstore.save_local("word_doc_faiss_index")
问答推理阶段(在线)
1. 用户提问
用户输入自然语言问题:
"RAG 技术的主要优势有哪些?"
2. 文档检索
过程:
- 将用户提出的问题向量化
- 在向量数据库中搜索相似度最高的前 N 个文档
- 返回最相关的文档片段
检索算法:
- 余弦相似度
- 欧氏距离
- 近似最近邻搜索
向量间的相似度计算
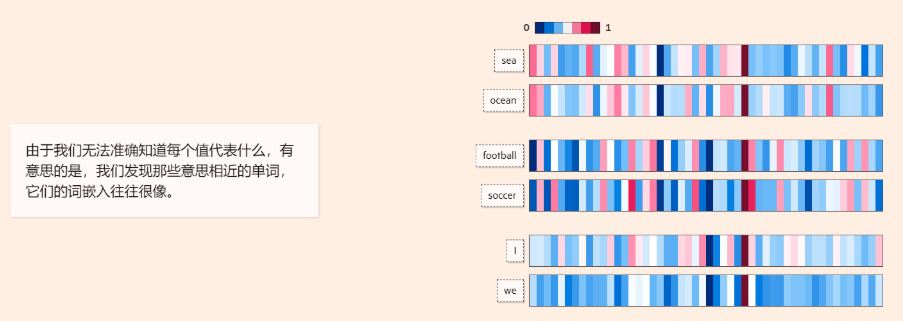
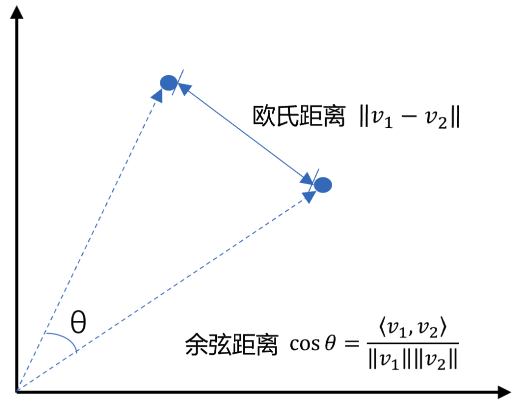
安装依赖:
pip install numpy
from openai import OpenAI
import os
import numpy as np
# NumPy 库中的线性代数模块
import numpy.linalg as norm
from dotenv import load_dotenv
load_dotenv()
client = OpenAI()
def cos_sim(a, b):
"""计算余弦相似度,数值越大越相似"""
return np.dot(a, b) / (norm.norm(a) * norm.norm(b))
def l2_dist(a, b):
"""计算欧氏距离,数值越小越相似"""
return norm.norm(np.asarray(a) - np.asarray(b))
def get_embedding(texts, model="text-embedding-3-small"):
"""
获取文本的 embedding 向量
参数:
texts: 字符串或字符串列表
model: 模型名称
返回:
如果 texts 是单个字符串,返回单个向量(列表)
如果 texts 是字符串列表,返回向量列表(列表的列表)
"""
# 确保 texts 是列表格式
if isinstance(texts, str):
texts = [texts]
response = client.embeddings.create(
model=model,
input=texts
)
# 返回所有文档的向量
embeddings = [item.embedding for item in response.data]
# 如果只有一个文本,返回单个向量;否则返回向量列表
return embeddings[0] if len(embeddings) == 1 else embeddings
# 支持跨语言计算
query = "Artificial Intelligence in Education"
documents = [
"机器学习算法正在改变传统教学模式,实现个性化学习�路径推荐",
"深度学习技术在自然语言处理领域的突破,使得智能辅导系统更加精准",
"计算机视觉技术帮助在线教育平台实现学生专注度监测和行为分析",
"大数据分析为教育决策提供数据支持,优化课程设计和教学资源配置",
"虚拟现实和增强现实技术创造沉浸式学习体验,提高学习效果和参与度",
]
# 进行转换 Embedding 向量
query_vec = get_embedding(query)
doc_vecs = get_embedding(documents)
print(f"查询向量维度: {len(query_vec)}")
print(f"文档数量: {len(doc_vecs)}")
print(f"每个文档向量维度: {len(doc_vecs[0])}")
print("余弦相似度计算:")
for i, vec in enumerate(doc_vecs):
cos_distance = cos_sim(query_vec, vec)
print(f"文档 {i+1}: {cos_distance:.4f}")
print("\n欧氏距离计算:")
for i, vec in enumerate(doc_vecs):
distance = l2_dist(query_vec, vec)
print(f"文档 {i+1}: {distance:.4f}")
向量数据库搜索查询文档
import os
# 设置 HuggingFace 镜像地址(国内加速)
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from langchain_community.vectorstores import FAISS
from langchain_huggingface import HuggingFaceEmbeddings
# 1. 加载已保存的 FAISS 向量数据库
embeddings = HuggingFaceEmbeddings(
model_name='BAAI/bge-large-zh-v1.5',
model_kwargs={'device': 'cpu'}
)
vectorstore = FAISS.load_local(
"word_doc_faiss_index", # 之前保存的目录名
embeddings,
allow_dangerous_deserialization=True # 必要的安全警告确认机制
)
# 2. 执行相似度搜索
query = "调休的申请流程是什么?"
docs_with_scores = vectorstore.similarity_search_with_score(query, k=3)
# 3. 打印检索结果
for doc, score in docs_with_scores:
print(f"相似度: {score:.4f} - 内容: {doc.page_content[:80]}...")
print("=" * 50)
3. 提示增强
目标:将检索到的文档与用户问题组合成增强提示
提示模板示例:
基于以下上下文信息,请回答问题:
【相关文档1】
RAG 技术可以接入最新数据,减少模型幻觉...
【相关文档2】
RAG 系统能够提供可验证的信息来源...
【相关文档3】
通过检索增强,模型可以回答专业领域问题...
问题:调休的申请流程是什么?
请根据上述上下文回答:
from langchain_core.prompts import ChatPromptTemplate
# 定义 RAG 提示词模板
template = """请根据以下上下文信息回答问题。如果上下文中有答案,请基于上下文回答;如果没有,请说明。
上下文信息:
{context}
问题:{question}
请给出详细、准确的回答:"""
prompt = ChatPromptTemplate.from_template(template)
4. 答案生成
目标:大语言模型基于增强提示生成最终答案
生成过程:增强提示 → 大语言模型 → 生成答案
模型选择:
- GPT 系列
- 文心一言、通义千问
- Llama、ChatGLM 等开源模型
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# 定义格式化文档的函数
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
from langchain_openai import ChatOpenAI
# 初始化 OpenAI 模型
llm_model = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0.7
)
# 创建检索器
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# 构建 LCEL 链
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm_model
| StrOutputParser()
)
# 使用示例
query = "调休的申请流程是什么?"
result = rag_chain.invoke(query)
print("用户提问:" + query)
print("模型最终回答:" + result)
完整流程演示
以下是一个从知识库构建到问答推理的完整代码示例:
import os
# 设置 HuggingFace 镜像地址(国内加速)
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 使用 LangChain 进行 Word 文档解析示例
from langchain_community.document_loaders import Docx2txtLoader
# 文档分割
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 向量数据库
from langchain_community.vectorstores import FAISS
# 向量化 Embedding
from langchain_huggingface import HuggingFaceEmbeddings
# LCEL Components
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
# ================= 1. �知识库构建 =================
# 初始化加载器,传入 Word 文档路径,加载文档为 Document 对象
loader = Docx2txtLoader("公司假期制度.docx")
documents = loader.load()
# 创建文本分割器,按照固定长度切分,并保留重叠部分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每个文本块的最大字符数
chunk_overlap=100, # 相邻文本块之间的重叠字符数(保持上下文连贯性)
separators=["\n\n", "\n", "。", "!", "?", ",", ""],
add_start_index=True,
)
# 执行分割
all_splits = text_splitter.split_documents(documents)
# 初始化 Embedding 模型
embeddings = HuggingFaceEmbeddings(
model_name='BAAI/bge-large-zh-v1.5',
model_kwargs={'device': 'cpu'}
)
# 创建向量数据库
vectorstore = FAISS.from_documents(all_splits, embeddings)
# 保存到本地(可选)
vectorstore.save_local("word_doc_faiss_index")
# ================= 2. 问答推理 =================
# 加载本地向量数据库存储
vectorstore = FAISS.load_local(
"word_doc_faiss_index",
embeddings,
allow_dangerous_deserialization=True
)
# 用户提问
query = "调休的申请流程是什么?"
# 创建检索器
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# 初始化 LLM
llm_model = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0.7
)
# 定义格式化函数
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 定义 RAG 提示词模板
template = """请根据以下上下文信息回答问题。如果上下文中有答案,请基于上下文回答;如果没有,请说明。
上下文信息:
{context}
问题:{question}
请给出详细、准确的回答:"""
prompt = ChatPromptTemplate.from_template(template)
# 构建 LCEL 链
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm_model
| StrOutputParser()
)
# 调用大模型回答内容
print("用户提问:" + query)
response = rag_chain.invoke(query)
print("模型最终回答:" + response)
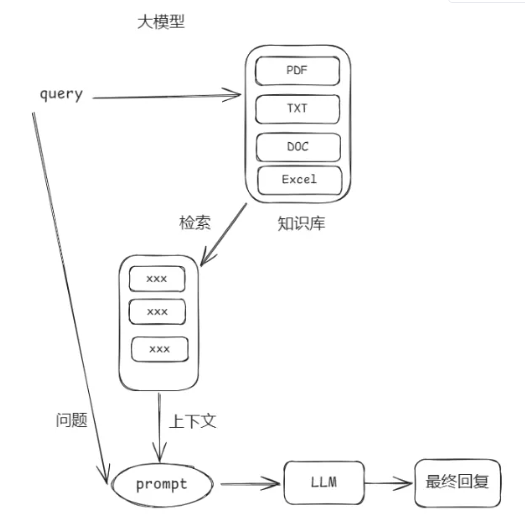
- 大模型个数和类别:整个 RAG 流程涉及到两类大模型
- 用于转换成向量的 Embedding 模型(用户提问阶段和知识库入库阶段的模型必须保持一致)
- 用于生成答案的 LLM 模型
- 语言模型应用场景:LLM 模型只负责最终将检索到的知识和用户问题进行整合后,回复用户
- 知识库的数据搭建工作不涉及 LLM 模型
- RAG 最终目的:这一系列操作都是为了整合好合适的 Prompt 提示词,最终交给 LLM
- Prompt 是与 LLM 大模型唯一的交互方式
RAG 实践落地策略与部署考虑
RAG 具体实践落地策略
- 手动搭建 RAG 引擎
- 低代码平台搭建(Coze、Dify、N8N)
- 使用 GLM、OpenAI Responses API 等进行快速实现
- 使用 LangChain、LlamaIndex 等开源项目快速搭建
实际部署考虑
在选择 RAG 应用场景时,需要考虑:
- 数据质量:是否有高质量、结构化的知识源?
- 更新频率:知识需要多频繁更新?
- 准确度要求:错误的代价有多大?
- 技术复杂度:是否有相应的技术能力?
RAG 应用优化方案
想要真正进一步优化 RAG 的效果,需要考虑:
-
优化文本分割:尝试不同的文本分割器(如按句子、递归字符等)和块大小、重叠长度。
-
重排序(Re-ranking):使用重排序模型对检索到的文档进行重新排序,以提高顶部文档的相关性。
-
多轮对话与历史管理:在对话中维护历史消息,并将历史信息纳入当前查询的上下文中。
-
混合检索:结合关键词检索(如 BM25)和向量检索,以及其他数据库,以提高检索的召回率。
-
评估与迭代:构建评估集,对 RAG 系统进行定量评估,从而指导优化方向。