会话式RAG与历史感知检索
本节介绍如何实现支持多轮对话的 RAG 系统,包括历史感知检索器和上下文问题重述技术。
核心概念
会话式 RAG
普通的 RAG 在处理多轮对话时存在一个问题:当用户说"它是怎么工作的?"时,模型不知道"它"指的是什么。
会话式 RAG 通过以下方式解决这个问题:
- 历史感知检索:利用对话历史理解用户意图
- 问题重述:将带有指代的问题重述为独立问题
两种 RAG 链对比
| 类型 | 说明 | 适用场景 |
|---|---|---|
| 普通 RAG | 单次检索,无历史记忆 | 简单问答 |
| 会话式 RAG | 支持多轮对话,理解上下文 | 复杂对话场景 |
工作流程
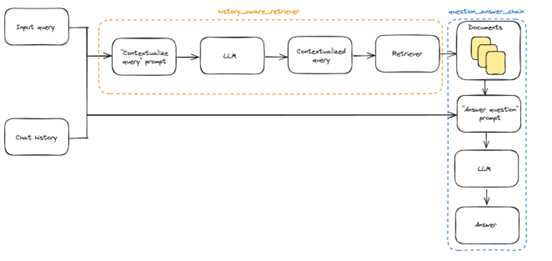
核心组件
| 组件 | LCEL 实现 |
|---|---|
| 历史感知检索器 | prompt | llm | retriever 管道 |
| 文档处理链 | RunnablePassthrough + lambda 组装上下文 |
| RAG 链 | | prompt | llm 管道串联 |
| 会话历史记忆 | RunnableWithMessageHistory |
代码实现
环境准备
# 安装依赖
pip install langchain langchain-community langchain-openai pymilvus beautifulsoup4
完整代码
import bs4
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory, RunnablePassthrough
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_milvus import Milvus
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from operator import itemgetter
# === 1. 初始化模型和嵌入 ===
# 使用 OpenAI(可替换为其他模型)
llm = ChatOpenAI(
model="gpt-4o-mini",
api_key="your-api-key",
base_url="https://api.openai.com/v1"
)
# 使用 BGE 嵌入模型
model_name = "BAAI/bge-small-zh-v1.5"
model_kwargs = {"device": "cpu"} # CPU 使用 cpu,显卡使用 cuda
encode_kwargs = {"normalize_embeddings": True} # 是否启用归一化
bge_embedding = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
# === 2. 构建 Milvus 向量数据库(线上 Milvus)===
vector_store = Milvus(
embedding_function=bge_embedding,
collection_name="t_agent_blog",
connection_args={
"uri": "https://your-cluster-id.zillizcloud.com", # 线上 Milvus 集群地址
"token": "your-api-key", # 线上 Milvus 的 API Key 或用户名:密码
},
auto_id=True
)
# === 3. 数据加载与存储(首次运行)===
def create_dense_db():
"""把关于 Agent 的博客数据写入 Milvus 向量数据库"""
loader = WebBaseLoader(
web_path=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
)
)
docs_list = loader.load()
# 文档切割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
splits = text_splitter.split_documents(docs_list)
print(f"文档数量: {len(splits)}")
vector_store.add_documents(documents=splits)
# 首次运行后注释掉
# create_dense_db()
# === 4. 问题重述提示词(LCEL 方式)===
# 将带有历史的问题重述为独立问题
contextualize_q_system_prompt = (
"给定聊天历史和最新的用户问题(可能引用聊天历史中的上下文),"
"将其重新表述为一个独立的问题(不需要聊天历史也能理解)。"
"不要回答问题,只需在需要时重新表述问题,否则保持原样。"
)
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
# === 5. 创建检索器 ===
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
# === 6. 创建历史感知检索器(LCEL 风格)===
# 使用 LCEL 管道:重述问题 -> 检索
contextualize_retriever = (
contextualize_q_prompt
| llm
| {"input": itemgetter("content")} # 提取重述后的问题
| retriever # 执行检索
)
# === 7. 问答提示词 ===
system_prompt = (
"你是一个问答任务助手。"
"使用以下检索到的上下文来回答问题。"
"如果不知道答案,就说你不知道。"
"回答最多三句话,保持简洁。"
"\n\n"
"{context}"
)
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
# === 8. 创建 RAG 链(LCEL 风格)===
# 检索 -> 组装上下文 -> 调用 LLM
rag_chain = (
contextualize_retriever
| (lambda docs: {"context": "\n\n".join(d.page_content for d in docs), "input": itemgetter("input")})
| qa_prompt
| llm
)
# === 9. 添加会话历史记忆 ===
store = {} # 保存历史消息,key: session_id
def get_session_history(session_id: str):
"""获取当前会话的历史消息"""
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 创建带历史记录功能的处理链
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
)
# === 10. 测试对话 ===
if __name__ == "__main__":
session_id = "abc123"
config = {"configurable": {"session_id": session_id}}
# 第一次提问
print("=" * 50)
print("用户: What is Task Decomposition?")
resp1 = conversational_rag_chain.invoke(
{"input": "What is Task Decomposition?"},
config=config
)
print(f"助手: {resp1.content}")
# 第二次提问(带上下文)
print("=" * 50)
print("用户: What are common ways of doing it?")
resp2 = conversational_rag_chain.invoke(
{"input": "What are common ways of doing it?"},
config=config
)
print(f"助手: {resp2.content}")
关键组件详解
问题重述
作用:将依赖历史的问题转换为独立问题。
| 用户输入 | 重述后 |
|---|---|
| "它是怎么工作的?" | "Task Decomposition 是怎么工作的?" |
| "还有其他方法吗?" | "除了 LLM with Python parser 还有其他方法吗?" |
历史感知检索器
# 使用 LCEL 管道实现问题重述 + 检索
contextualize_retriever = (
contextualize_q_prompt # 1. 构建提示词
| llm # 2. 调用 LLM 重述问题
| {"input": itemgetter("content")} # 3. 提取重述后的问题
| retriever # 4. 执行向量检索
)
RAG 链
# 使用 LCEL 管道实现检索 + 生成
rag_chain = (
contextualize_retriever # 1. 历史感知检索
| (lambda docs: { # 2. 组装上下文
"context": "\n\n".join(d.page_content for d in docs),
"input": itemgetter("input")
})
| qa_prompt # 3. 构建问答提示词
| llm # 4. 调用 LLM 生成回答
)
工作原理:
- 接收用户问题和聊天历史
- 让 LLM 重述问题为独立问题
- 用重述后的问题进行向量检索
- 检索相关文档
- 组装上下文并生成回答
会话历史管理
# 存储结构
store = {
"session_id_1": [UserMsg, AssistantMsg, UserMsg, ...],
"session_id_2": [...],
}
# 获取历史
def get_session_history(session_id: str):
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
完整流程图
参数说明
| 参数 | 说明 |
|---|---|
chunk_size | 文档切割块大小 |
chunk_overlap | 块之间重叠大小 |
k | 检索返回结果数量 |
session_id | 会话唯一标识 |
input_messages_key | 输入消息的键名 |
history_messages_key | 历史消息的键名 |
output_messages_key | 输出消息的键名 |