全文检索
全文检索(BM25)
全文检索(BM25)是一种通过匹配关键词来检索文档的方法,根据词频等因素计算相关性分数排序。
说明:与近似近邻检索(ANN)的语义理解不同,全文检索擅长精确关键词匹配,两者是互补关系。ANN 找"意思相近"的,全文检索找"包含关键词"的。
全文搜索通过BM25算法实现精确的术语匹配,自动将文本转换为稀疏嵌入,克服了语义搜索可能忽略精确词的局限,在RAG场景中能优先检索出高度相关的文档。
-
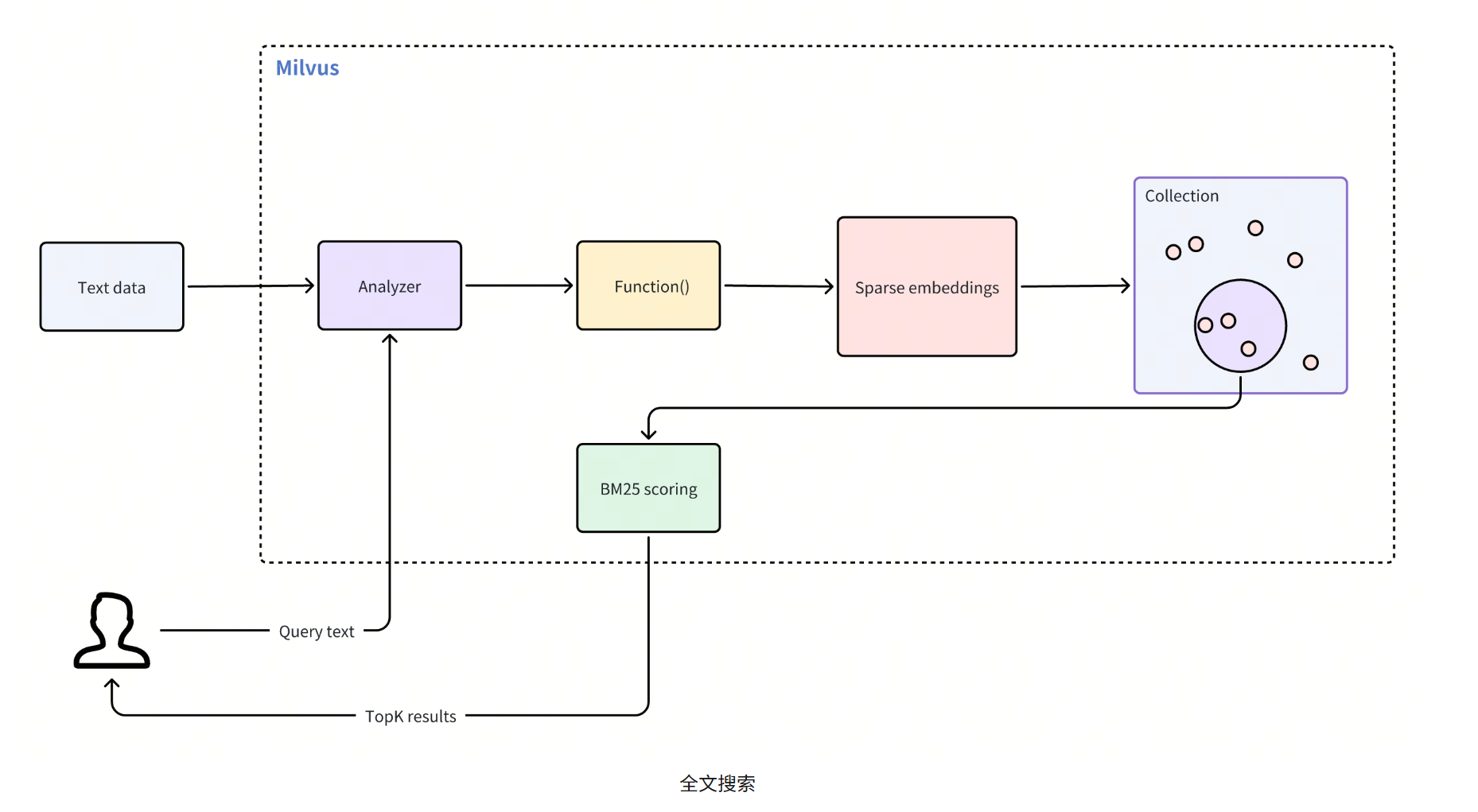
原始文本输入:插入文本文档或使用纯文本提供查询,无需嵌入模型。
-
文本分析:Milvus 使用分析器将您的文本处理成可索引和搜索的有意义术语。
-
BM25 函数处理:一个内置函数可将这些术语转换为针对 BM25 评分优化的稀疏向量表示。
-
Collections 存储:Milvus 将生成的稀疏嵌入存储在一个 Collections 中,以便快速检索和�排序。
-
BM25 相关性评分:在搜索时,Milvus 应用 BM25 评分函数计算文档相关性,并返回与查询词最匹配的排序结果。
Analyzer 分词
分词是全文检索的基础,需要根据不同语言配置:
| 语言 | 分词器 | 配置 |
|---|---|---|
| 英文 | 英文分词器 | 默认 |
| 中文 | jieba 分词器(推荐) | analyzer_params={'tokenizer': 'jieba'} |
| 中文 | 中文分词器 | analyzer_params={'type': 'chinese'} |
使用步骤
要使用全文搜索,请遵循以下主要步骤:
- 创建 Collections:设置一个带有必要字段的 Collections,并文本转换为稀疏嵌入定义一个将原始的函数
- 插入数据:将原始文本文档插入 Collections
- 执行搜索:使用查询文本搜索你的 Collections 并检索相关结果
代码示例
1. 创建 Collection
from langchain_milvus import Milvus, BM25BuiltInFunction
from pymilvus import MilvusClient, DataType, Function, FunctionType
from utils.env_utils import MILVUS_URI
def create_collection():
"""创建一个支持全文检索的 Collection"""
client = MilvusClient(uri=MILVUS_URI)
schema = client.create_schema()
schema.add_field(field_name='id', datatype=DataType.INT64, is_primary=True, auto_id=True)
schema.add_field(field_name='text', datatype=DataType.VARCHAR, enable_analyzer=True, analyzer_params={'type': 'chinese'}, max_length=6000)
schema.add_field(field_name='category', datatype=DataType.VARCHAR, max_length=1000)
schema.add_field(field_name='sparse', datatype=DataType.SPARSE_FLOAT_VECTOR)
# 定义 BM25 函数
bm25_function = Function(
name='text_bm25_emb',
input_field_names=['text'],
output_field_names=['sparse'],
function_type=FunctionType.BM25
)
schema.add_function(bm25_function)
# 配置索引(全文检索必须创建索引)
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse",
index_name="sparse_inverted_index",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
params={
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.6,
"bm25_b": 0.75
},
)
collection_name = 'demo2'
# 创建表
if collection_name in client.list_collections():
client.release_collection(collection_name=collection_name)
client.drop_index(collection_name=collection_name, index_name='sparse_inverted_index')
client.drop_collection(collection_name=collection_name)
client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params,
)
2. 插入数据
from document.markdown_parser import MarkdownParser
from langchain_milvus import Milvus, BM25BuiltInFunction
def insert_data():
"""往 Collection 中插入数据"""
file_path = r'C:\Users\21129\PycharmProjects\RAG_PROJECT\data\md\tech_report_0tfhhamx.md'
parser = MarkdownParser()
docs = parser.parse_markdown_to_documents(file_path)
vector_store = Milvus(
embedding_function=None, # 不用处理密集向量
collection_name='demo2',
builtin_function=BM25BuiltInFunction(output_field_names='sparse'),
vector_field=['sparse'],
consistency_level='Strong',
auto_id=True,
connection_args={'uri': MILVUS_URI}
)
vector_store.add_documents(docs)
print('插入完毕')
3. 全文搜索测试
def search():
"""全文搜索测试"""
vector_store = Milvus(
embedding_function=None,
collection_name='demo2',
builtin_function=BM25BuiltInFunction(output_field_names='sparse'),
vector_field=['sparse'],
consistency_level='Strong',
auto_id=True,
connection_args={'uri': MILVUS_URI}
)
res = vector_store.similarity_search_with_score(
query='活性氧原子',
k=2
)
for doc in res:
print(doc)
if __name__ == '__main__':
create_collection()
insert_data()
search()
搜索结果示例
(Document(
metadata={'category': 'content', 'id': 464302355161322620},
page_content='等离子体处理改善半导体材料表面特性的技术与方法 -> ...活性氧原子氧化分解有机物...'
), 3.809553861618042)
(Document(
metadata={'category': 'content', 'id': 464302355161322628},
page_content='等离子体处理改善半导体材料表面特性的技术与方法 -> ...'
), 3.208083152770996)
中文分词配置
在创建字段时,可以通过 analyzer_params 指定分词器类型:
# 开启中文分词
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
enable_analyzer=True,
analyzer_params={'type': 'chinese'},
max_length=6000
)
| 参数 | 说明 |
|---|---|
enable_analyzer | 是否启用分析器 |
analyzer_params | 分词器配置 |
jieba 分词器配置
Milvus 支持使用 jieba 作为中文分词器,配置示例:
# 使用 jieba 分词器
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
enable_analyzer=True,
analyzer_params={'tokenizer': 'jieba', 'filter': ['cnalphanumonly']},
max_length=6000
)
参数说明:
| 参数 | 说明 |
|---|---|
tokenizer | 分词器类型,jieba 表示使用 jieba 分词器 |
filter | 过滤器,cnalphanumonly 表示只保留中文、字母、数字 |
完整示例:
from langchain_milvus import Milvus, BM25BuiltInFunction
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(uri=MILVUS_URI)
schema = client.create_schema()
schema.add_field(field_name='id', datatype=DataType.INT64, is_primary=True, auto_id=True)
schema.add_field(field_name='text', datatype=DataType.VARCHAR, enable_analyzer=True,
analyzer_params={'tokenizer': 'jieba', 'filter': ['cnalphanumonly']}, max_length=6000)
schema.add_field(field_name='category', datatype=DataType.VARCHAR, max_length=1000)
schema.add_field(field_name='sparse', datatype=DataType.SPARSE_FLOAT_VECTOR)
bm25_function = Function(
name='text_bm25_emb',
input_field_names=['text'],
output_field_names=['sparse'],
function_type=FunctionType.BM25
)
schema.add_function(bm25_function)
# 配置索引
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse",
index_name="sparse_inverted_index",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
params={
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.6,
"bm25_b": 0.75
},
)
collection_name = 'demo2'
client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params,
)
PyMilvus 原生搜索
除了使用 LangChain,也可以直接使用 PyMilvus 进行全文检索:
def test5():
"""使用 PyMilvus 原生检索"""
client = MilvusClient(uri=MILVUS_URI)
res = client.search(
collection_name='demo2',
data=['活性氧原子'],
anns_field='sparse',
limit=3,
output_fields=['text', 'id', 'category'],
# search_params={"params": {'drop_ratio_search': 0.2}}
)
for item in res[0]:
print(item)