混合检索和重排
本文介绍 RAG 系统中的混合搜索技术和重排序策略。
混合搜索
混合搜索指的是同时进行多个 ANN 搜索,对这些 ANN 搜索的多组结果进行 Rerank 并最终返回一组结果的搜索方法。使用混合搜索可以提高搜索精度。
核心思路:同时使用稀疏搜索和密集搜索,同一个关键词、同一句话会产生两种搜索结果,搜索完之后再进行 Rerank。
应用场景
不同类型的向量可以表示不同的信息,使用各种嵌入模型可以更全面地表示数据的不同特征和方面。
稀疏-密集向量搜索
| 向量类型 | 特点 | 适用场景 |
|---|---|---|
| 稀疏向量 | 维度高,非零值少,词频统计 | 传统信息检索、关键词匹配 |
| 密集向量 | 神经网络生成,捕捉语义 | 语义搜索、概念理解 |
- 稀疏向量:适合涉及文本匹配的任务,每个维度对应语言中的词块
- 密集向量:即使没有精确文本匹配,也能根据向量距离返回最相似的结果
多模态搜索
跨多种模态(图像、视频、音频、文本等)进行相似性搜索。例如,用指纹、声纹和面部特征等多种数据模式表示一个人。
工作流程
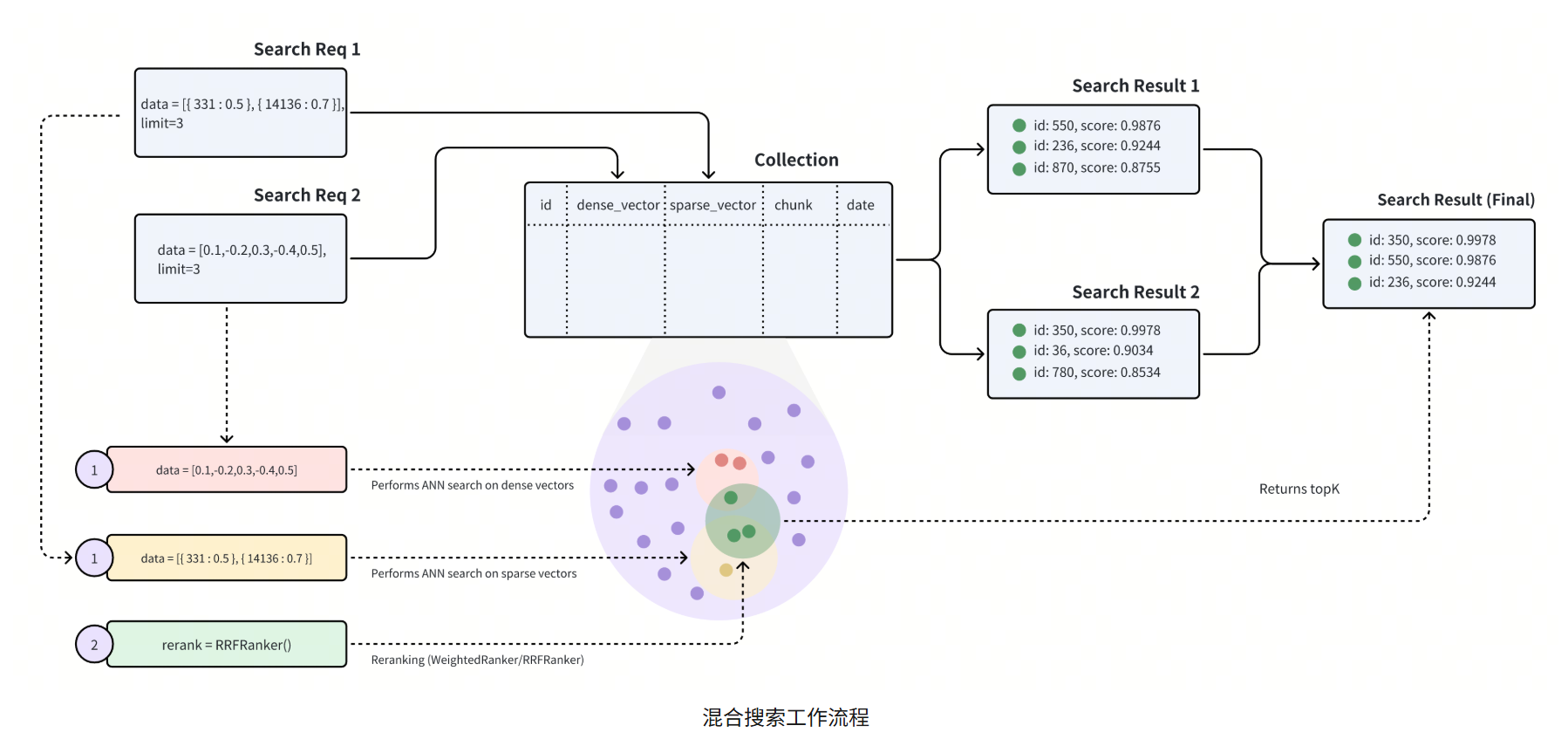
流程说明:
- 生成密集向量:通过 BERT、Transformers 等嵌入模型
- 生成稀疏向量:通过 BM25、BGE-M3、SPLADE 等嵌入模型
- 创建 Collection:包含密集向量场和稀疏向量场
- 插入向量:将稀疏密集向量插入 Collection
- 混合搜索:ANN 搜索返回两组 Top-K 结果
- 归一化:将得分转换为 [0,1] 范围
- 重排:合并和重排两组结果,返回最终 Top-K
重排策略
重排(Rerankers)将用于关键词匹配的 BM25 和用于语义检索的向量搜索结合在一起,来自这两种方法的结果经过合并、Rerankers 和传递给 LLM 来生成最终答案。
下图展示了在 Milvus 中执行混合搜索的过程,并强调了重排在此过程中的作用。
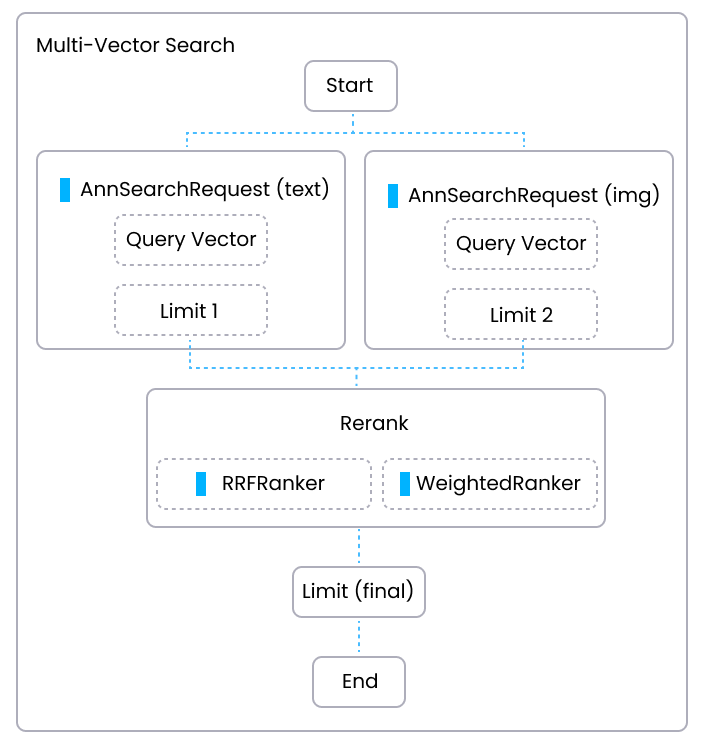
混合搜索中的重新排序是一个关键步骤,它可以整合来自多个向量场的结果,确保最终输出结果具有相关性并能准确排出优先级。
WeightedRanker(加权评分)
根据每个向量字段的重要性,为每个向量检索路径的结果分配不同的权重。
适用场景:每个向量字段重要性不同时,如多模态搜索中文本描述比图像颜色更重要。
示例:
# 稀疏向量权重 0.6,密集向量权重 0.4
weights = [0.6, 0.4]
RRFRanker(互易等级融合)
根据排名倒数来组合排名列表,平衡各向量场的影响。
计算公式:
其中:
- :不同检索路径的数量
- :第 个检索器检索到的文档 的排名位置
- :平滑参数,通常设置为 60
k 参数影响:
| k 值 | 特点 |
|---|---|
k=60 | 更倾向稀疏向量检索的高排名项 |
k=100 | 平衡双方权重 |
示例:
假设两路检索结果:
- 稠密向量检索:文档A排名第1,文档B排名第5
- 稀疏向量检索:文档A排名第3,文档B排名第1
| 文档 | k=60 得分 | k=100 得分 | k=60 胜出 | k=100 胜出 |
|---|---|---|---|---|
| 文档A | 0.032 | 0.020 | ||
| 文档B | 0.034 | 0.019 | ✅ |
代码示例
1. PyMilvus 原生混合检索
from pymilvus import MilvusClient, AnnSearchRequest, RRFRanker
from llm_models.embeddings_model import bge_embedding
from utils.env_utils import MILVUS_URI, COLLECTION_NAME
def test7():
"""PyMilvus 原生混合检索"""
client = MilvusClient(uri=MILVUS_URI)
# 密集向量搜索请求
search_params_1 = {
'data': [bge_embedding.embed_query('现在,最先进的纳米级清洗技术是什么 ')],
'anns_field': 'dense',
'param': {
'metric_type': 'IP',
'params': {'nprobe': 10}
},
'limit': 5
}
req1 = AnnSearchRequest(**search_params_1)
# 稀疏向量搜索请求(BM25 算法是 Milvus 内置的,只需传递文本)
search_params_2 = {
'data': ['纳米级清洗技术是什么'],
'anns_field': 'sparse',
'param': {'metric_type': 'BM25',},
'limit': 5
}
req2 = AnnSearchRequest(**search_params_2)
# 执行混合搜索
res = client.hybrid_search(
collection_name=COLLECTION_NAME,
reqs=[req1, req2], # 多个搜索请求
ranker=RRFRanker(60), # RRF 重排,k=60
limit=5,
output_fields=['text', 'title', 'category']
)
for hits in res:
print('TopN的结果')
for item in hits:
print(item)
返回结果示例:
TopN的结果
{'id': 464302355161324113, 'distance': 0.032, 'entity': {'category': 'content', 'text': '半导体制造中的纳米级污染物清洁工艺...', 'title': '湿法清洗(Wet Cleaning)'}}
{'id': 464302355161324114, 'distance': 0.032, 'entity': {'category': 'content', 'text': '半导体制造中的纳米级污染物清洁工艺...', 'title': '干法清洗(Dry Cleaning)'}}
2. LangChain-Milvus 混合检索
def test8():
"""使用 LangChain-Milvus 进行混合检索"""
mv = MilvusVectorSave()
mv.create_connection()
res = mv.vector_store_saved.similarity_search_with_score(
query='现在,最先进的纳米级清洗技术是什么 ',
k=3,
ranker_type='rrf', # 或 'weighted'
ranker_params={'k': 100}, # RRF 平滑参数
)
for item in res:
print(item)
3. LangChain Retriever 混合检索
def test9():
"""使用 LangChain Retriever 进行混合检索"""
mv = MilvusVectorSave()
mv.create_connection()
# 创建检索器
retriever = mv.vector_store_saved.as_retriever(
search_type='similarity',
search_kwargs={
'k': 3,
'score_threshold': 0.1,
'ranker_type': 'rrf',
'ranker_params': {'k': 100},
'filter': {'category': 'content'} # 过滤检索
}
)
res = retriever.invoke('介绍一下,光刻机有哪几种?')
for item in res:
print(item)
as_retriever() 函数参数
在 LangChain-Milvus 库中,as_retriever() 函数用于将向量存储转换为检索器。
search_type 参数
| 参数值 | 说明 |
|---|---|
"similarity"(默认) | 基于向量相似度的简单搜索 |
"mmr" | Maximal Marginal Relevance,在相似度基础上增加多样性,避免返回重复内容 |
search_kwargs 参数
| 参数 | 说明 |
|---|---|
k | 返回的最近邻数量 |
score_threshold | 相似度分数阈值,仅返回分数高于此值的结果 |
ranker_type | 重排类型:rrf 或 weighted |
ranker_params | 重排参数,如 {'k': 100} |
filter / expr | Milvus 的原生过滤表达式(如按元数据过滤) |
nprobe 参数
用于 Milvus/FAISS 等向量数据库的 ANN 搜索,属于 IVF 类索引的核心参数。
| 特点 | 说明 |
|---|---|
| 作用 | 控制搜索时访问的聚类中心(桶)数量 |
| 值越大 | 搜索范围越广,召回率越高,但计算量增加 |
| 值越小 | 搜索速度越快,但可能遗漏相关结果 |
示例:若索引有 1024 个聚类中心(nlist=1024),nprobe=10 表示仅搜索距离查询向量最近的 10 个聚类中心内的向量。
过滤表达式
Milvus 支持在搜索时使用过滤表达式进行条件筛选。
常用示例
# 数值比较
filter = "price < 100"
filter = "rating >= 4.5"
# 字符串匹配
filter = "category == '科技'"
filter = "author in ['Alice', 'Bob']"
# 逻辑组合
filter = "price < 100 AND category == '科技'"
filter = "status == 1 OR is_featured == true"
过滤操作符
| 类型 | 操作符 | 说明 |
|---|---|---|
| 比较 | ==, !=, >, <, >=, <= | 基于数字、文本或日期字段筛选 |
| 范围 | IN, LIKE | 匹配特定的值范围或集合 |
| 逻辑 | AND, OR, NOT | 组合多个条件 |