密集嵌入与稀疏嵌入
在 RAG(Retrieval-Augmented-Generation)的混合检索中,密集嵌入(Dense Embedding)和稀疏嵌入(Sparse Embeddings) 是两种互补的向量表示方法,分别用于捕捉语义信息和关键词匹配。
混合检索概念
混合搜索结合了不同搜索范式的优势,以提高检索的准确性和鲁棒性。它充分利用了密集向量搜索和稀疏向量搜索的能力,确保对各种查询进行全面而准确的检索。
在这种情况下,使用语义向量相似性和精确关键词匹配两种方法检索候选内容。来自这些方法的结果会被合并、重新排序,并传递给 LLM 以生成最终答案。这种方法兼顾了精确性和语义理解,对各种查询场景都非常有效。
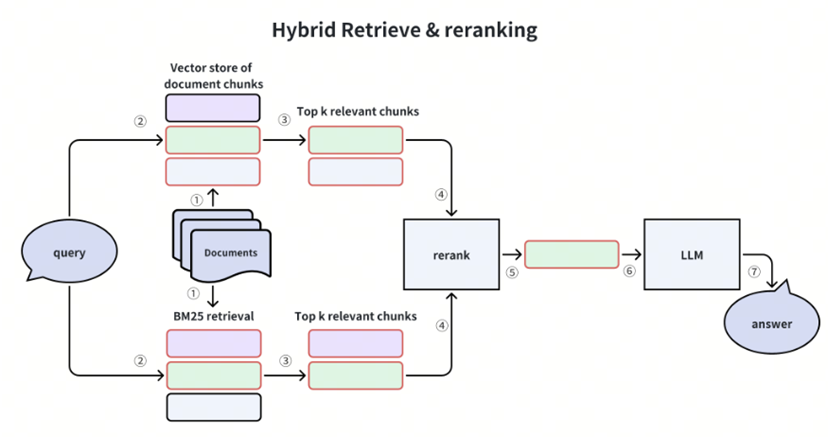
两种形式的向量都要存储到向量数据库中:
- 密集嵌入(Dense Embeddings):用于捕捉语义信息,找到语义最相近的向量
- 稀疏嵌入(Sparse Embeddings):用于关键词匹配,ElasticSearch 中采用的就是稀疏嵌入
密集嵌入模型
密集嵌入模型将文本转换为稠密的向量表示,适合语义相似度匹配。
选择对比
| 模型 | 提供商 | 维度 | 是否收费 | 特点 |
|---|---|---|---|---|
| bge-large-zh-v1.5 | 智源研究院(BAAI) | 1024 | 免费开源 | 中文效果优秀 |
| bge-small-zh-v1.5 | 智源研究院(BAAI) | 512 | 免费开源 | 轻量级,速度快 |
| text-embedding-3-small | OpenAI | 1536 | API收费 | 全球通用 |
| text-embedding-3-large | OpenAI | 3072 | API收费 | 效果最好 |
BGE-Large 安装和使用
pip install --upgrade --quiet sentence_transformers
from langchain_huggingface import HuggingFaceEmbeddings
model_name = "BAAI/bge-large-zh-v1.5"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
bge_embedding = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
embeddings = bge_embedding.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
print(len(embeddings), len(embeddings[0]))
embedded_query = bge_embedding.embed_query("What was the name mentioned in the conversation?")
print(embedded_query)
OpenAI Embeddings 使用
from langchain_openai import OpenAIEmbeddings
openai_embedding = OpenAIEmbeddings(
model="text-embedding-3-small",
openai_api_key="your-api-key"
)
# 生成向量
vector = openai_embedding.embed_query("你的查询文本")
normalize_embeddings 参数说明
在 HuggingFaceBgeEmbeddings 中,normalize_embeddings 参数用于决定是否对生成的嵌入向量进行归一化处理:
| 值 | 说明 |
|---|---|
True | 生成的嵌入向量会被归一化为单位向量,L2 范数为 1 |
False | 生成的嵌入向量保持原始数值,不进行归一化处理 |
归一化的优点:
- 提高相似度计算的稳定性:归一化后的向量可以避免因向量长度不同而导致的相似度偏差
- 一致性:归一化可以确保不同批次或不同模型生成的嵌入向量在同一尺度上,便于比较和整合
BM25 稀疏嵌入详解
BM25(Best Matching 25)是一种 基于统计的稀疏检索算法,是信息检索(IR)领域最经典的排序函数之一。它是对传统 TF-IDF(词频-逆文档频率) 的�改进,能够更合理地衡量文档与查询的相关性,广泛用于搜索引擎(如 ElasticSearch、Lucene)和问答系统。
BM25 的核心思想
BM25 的核心是计算查询(Query) 和 文档(Document) 之间的相关性得分,主要考虑以下因素:
- 词频(Term Frequency, TF):查询词在文档中出现的频率(越高越相关)
- 逆文档频率(Inverse Document Frequency, IDF):查询词在整个语料库中的稀有程度(越稀有越重要)
- 文档长度归一化(Document Length Normalization):避免长文档因词频高而占据优势
BM25 公式
BM25 的公式比 TF-IDF 更精细,引入了可调参数(k₁ 和 b),使其对不同数据集更鲁棒:


参数说明
k₁:词频饱和度参数,控制词频增长对得分的影响速度,通常取��值 1.2-2.0b:文档长度归一化参数,控制文档长度对得分的影响程度,通常取值 0.75
Milvus 中使用 BM25
在 Milvus 中,可以通过 Function 来自动将文本字段转换为稀疏向量(BM25)。
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(uri='http://152.136.163.231:19530')
# 先删除旧的 collection
client.drop_collection(collection_name='t_demo2')
# 定义 Collections 模式 (三个字段)
schema = client.create_schema()
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True)
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=2000, enable_analyzer=True)
schema.add_field(field_name="sparse", datatype=DataType.SPARSE_FLOAT_VECTOR) # 存储稀疏嵌入后的值
# 进行稀疏嵌入的函数:从一个字段中读取原始数据,通过bm25算法,转换为向量,再把稀疏向量存到输出字段
bm25_function = Function(
name="text_bm25_emb", # Function name
input_field_names=["text"], # Name of the VARCHAR field containing raw text data
output_field_names=["sparse"], # Name of the SPARSE_FLOAT_VECTOR field reserved to store generated embeddings
function_type=FunctionType.BM25, # Set to `BM25`
)
schema.add_function(bm25_function)
# 配置索引
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse",
index_name="sparse_inverted_index",
index_type="SPARSE_INVERTED_INDEX", # Inverted index type for sparse vectors
metric_type="BM25",
params={
"inverted_index_algo": "DAAT_MAXSCORE", # Algorithm for building and querying the index
"bm25_k1": 1.6, # 范围:[1.2 ~ 2.0]
"bm25_b": 0.75
},
)
# 创建一张表
client.create_collection(
collection_name='t_demo2',
schema=schema,
index_params=index_params
)
# 插入测试数据(sparse 字段由 BM25 函数自动计算,不需要手动提供)
client.insert('t_demo2', [
{'text': 'information retrieval is a field of study.'},
{'text': 'information retrieval focuses on finding relevant information in large datasets.'},
{'text': 'data mining and information retrieval overlap in research.'},
])
# 开始进行匹配搜索(全文搜索)
search_params = {
'params': {'drop_ratio_search': 0.2}, # 搜索时要忽略的低重要性词语的比例
}
resp = client.search(
collection_name='t_demo2',
data=['whats the focus of information retrieval?'],
anns_field='sparse', # 匹配的稀疏向量字段
limit=3,
search_params=search_params,
output_fields=["text"]
)
print(resp)
代码说明:
Function是 Milvus 的内置函数,用于自动将文本转换为向量input_field_names指定要处理的文本字段output_field_names指定生成的稀疏向量存储字段enable_analyzer=True启用文本分析器,用于分词
搜索结果示例:
# [[{'id': 464302355161319771, 'distance': 1.3473916053771973, 'entity': {'text': 'information retrieval is a field of study.'}}, ...]]