什么是Embedding模型
基本概念
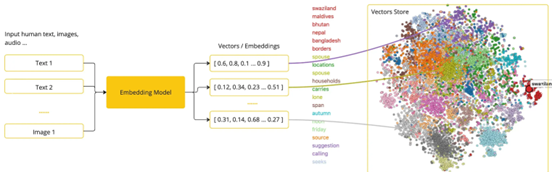
Embedding模型是将高维度的数据(例如文字、图片、视频)映射到低维度空间的过程。简单来说,embedding向量就是一个 N 维的实值向量,它将输入的数据表示成一个连续的数值空间中的点。
Embeddings 的学习通常基于无监督或弱监督的方法。对于自然语言处理任务,常用的 Embeddings 方法包括 Word2Vec、GloVe 和 FastText。这些方法可以从大规模的文本语料库中学习单词的分布式表示。对于计算机视觉任务,常用的 Embeddings 方法包括卷积神经网络(CNN)和循环神经网络(RNN)等。
通俗理解:嵌入就相当于给文本穿上了"数字化"的外衣,目的是让机器更好的理解和处理。
发展历程
静态词嵌入
最早的嵌入方法是静态的 Word Embedding,典型代表:
| 模型 | 说明 |
|---|---|
| Word2Vec | Google 提出,通过 CBOW 或 Skip-gram 训练词向量 |
| GloVe | Stanford 提出,基于全局词频统计 |
| FastText | Facebook 提出,考虑子词信息 |
动态预训练模型
随着深度学习发展,出现了能生成上下文相关 embedding 的预训练模型:
Word2Vec → GloVe → FastText → ELMo → BERT → GPT → GPT-2 → GPT-3 → ALBERT → XLNet
大型语言模型可以生成上下文相关的 embedding 表示,可以更好地捕捉单词的语义和上下文信息。
向量空间
所有的数据都变成向量,这些向量组成一个庞大的矩阵。在这个世界里,每个词、句子、图片、用户…都被表示成一个"点"(即向量),大家都有自己的"坐标"。
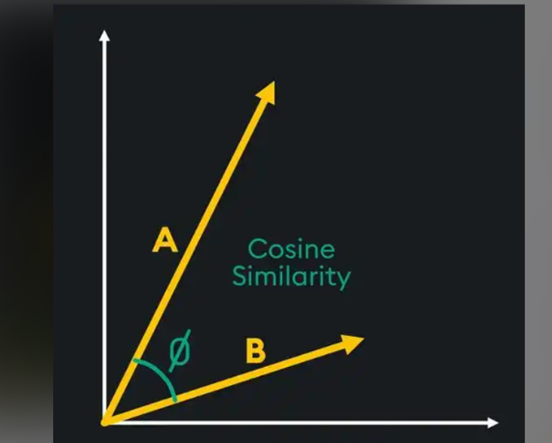
我们可以通过距离和方向来理解它们的关系。
距离表示相似度
- 向量之间越近:意义越相似
- 向量之间越远:意义越不同
例如:
- "苹果" 和 "香蕉" 的向量夹角小(��近)→ 都是水果
- "苹果" 和 "MacBook" 的向量略远 → 一个是水果,一个是电子产品
Embedding 向量的作用
解决的问题
| 问题 | 说明 |
|---|---|
| 降维 | 在高维度空间中,数据点之间可能存在很大的距离,使得样本稀疏,嵌入模型可以减少数据稀疏性 |
| 捕捉语义信息 | Embedding 不仅仅是降维,更重要的是,它能够捕捉到数据的语义信息。语义相近的词在向量上也是相近的 |
| 特征表示 | 原始数据的特征往往难以直接使用,通过嵌入模型可以将特征转换成更有意义的表示 |
| 计算效率 | 在低维度空间中对数据进行处理和分析往往更加高效 |
独热编码 vs Embedding
独热编码
是一种将数据转换为二进制向量的技术。它的主要目的是将分类变量转换为机器学习算法能够处理的格式,从而避免数值关系的误判。
举例:词表中有 10,000 个词,每个词都用一个只有一个 1、其它全是 0 的向量来表示。
这样的向量是:
- 📏 高维:非常长(比如 10k、100k…)
- ⚪ 稀疏:只有一个 1,其他都是 0
- 🧱 没有语义信息:"猫"和"狗"之间毫无关系
Embedding 的优势
| 维度 | 独热编码 | Embedding |
|---|---|---|
| 维度 | 高维(词表大小) | 低维(通常 128-4096) |
| 稀疏性 | 极度稀疏 | 密集 |
| 语义 | 无语义信息 | 蕴含语义关系 |
| 计算 | 效率低 | 高效 |
Embeddings 模型创建文本片段的向量表示。您可以将向量视为一个数字数组,它捕捉了文本的语义含义。通过这种方式表示文本,您可以执行数学运算,从而进行诸如搜索其他在意义上最相似的文本等操作。
使用场景
-
机器学习通用:Embeddings 可以在各种机器学习任务中使用,包括分类、聚类、检索和推荐等
-
自然语言处理:
- 使用静态预训练的 Embeddings 模型,如 Word2Vec、GloVe 和 FastText
- 可用于情感分析、命名实体识别、机器翻译等任务
-
计算机视觉:
- 使用 CNN 提取图像的特征向量
- 通过图像与文本联合训练,学习图像和文本之间的语义关系
-
RAG 开发:
- 创建向量数据库时,使用 Embedding 模型对文本进行向量化处理
- 检索时,对用户输入进行向量化处理
LangChain 中的 Embeddings
LangChain 提供了一个标准接口 Embeddings 类来与各种嵌入模型供应商交互。
from langchain_openai import OpenAIEmbeddings
from env_utils import OPENAI_API_KEY
openai_embedding = OpenAIEmbeddings(
openai_api_key=OPENAI_API_KEY,
openai_api_base="https://xiaoai.plus/v1",
model = 'text-embedding-3-large',
dimensions=256
)
# 嵌入文档(待搜索的内容)
docs = ["第一个文档", "第二个文档"]
doc_vectors = openai_embedding.embed_documents(docs)
print(doc_vectors)
# 嵌入查询(搜索查询)
query = "用户的问题"
query_vector = openai_embedding.embed_query(query)
print(query_vector)
两个核心方法
| 方法 | 说明 |
|---|---|
embed_documents | 嵌入多个文档,接受多个文本输入,返回向量列表的列表 |
embed_query | 嵌入单个查询文本,返回向量列表 |
注意:某些嵌入模型供应商对文档和查询有不同的嵌入方法,因此 LangChain 分离了这两个方法。
常见 Embedding 模型供应商
- OpenAI:text-embedding-3-small / text-embedding-3-large
- Hugging Face:BGE 系列、Sentence-BERT
- BGE(BAAI):BGE-Large-ZH、BGE-M3
- Cohere:embed-multilingual
选择 Embedding 模型时需考虑:语言支持、维度、效果、速度、成本等因素。