Milvus基础操作与混合存储
本文档介绍如何使用 Milvus 向量数据库进行混合向量存储。
环境配置
安装依赖
pip install pymilvus langchain-milvus langchain-huggingface langchain-openai sentence-transformers
初始化嵌入模型
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_openai import OpenAIEmbeddings
# OpenAI 嵌入
openai_embedding = OpenAIEmbeddings(
openai_api_key=OPENAI_API_KEY,
openai_api_base="https://xiaoai.plus/v1"
)
# BGE 嵌入(开源免费)
model_name = "BAAI/bge-small-zh-v1.5"
model_kwargs = {"device": "cpu"} # CPU 使用 cpu,显卡使用 cuda
encode_kwargs = {"normalize_embeddings": True} # 是否启用归一化
bge_embedding = HuggingFaceEmbeddings(
model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs
)
Hello World 快速入门
本节通过一个简单示例介绍 Milvus 的基本 CRUD 操作。
from pymilvus import MilvusClient # Milvus 客户端,用于操作嵌入式向量数据库
import numpy as np # NumPy 库,用于生成随机数和处理数组
# 初始化 Milvus 客户端
client = MilvusClient(uri='http://152.136.163.231:19530')
client.drop_collection(collection_name='demo_collection')
# 创建集合(Collection)
# 集合类似于关系型数据库中的表,用于存储向量和其他字段
client.create_collection(
collection_name="demo_collection", # 集合名称
dimension=384 # 向量的维度为 384
)
# 准备数据:文档、向量和其他字段
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.", # 文档 1
"Alan Turing was the first person to conduct substantial research in AI.", # 文档 2
"Born in Maida Vale, London, Turing was raised in southern England.", # 文档 3
]
# 为每段文本生成一个随机的 384 维向量
vectors = [[np.random.uniform(-1, 1) for _ in range(384)] for _ in range(len(docs))]
# 将文档、向量、ID 和主题打包成字典格式
data = [
{"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"}
for i in range(len(vectors))
]
# 将数据插入到集合中
res = client.insert(
collection_name="demo_collection",
data=data
)
print("Insert result:", res)
# 执行相似性搜索
res = client.search(
collection_name="demo_collection",
data=[vectors[0]],
filter="subject == 'history'",
limit=2,
output_fields=["text", "subject"],
)
print("Search result:", res)
# 执行查询操作(类似 SQL 查询)
res = client.query(
collection_name="demo_collection",
filter="subject == 'history'",
output_fields=["text", "subject"],
)
print("Query result:", res)
# 删除记录
res = client.delete(
collection_name="demo_collection",
filter="subject == 'history'",
)
print("Delete result:", res)
运行结果:
Insert result: {'insert_count': 3, 'ids': [0, 1, 2]}
Search result: [[{'id': 0, 'distance': 1.0, 'entity': {...}}, {'id': 1, 'distance': 0.026, 'entity': {...}}]]
Query result: [{'id': 0, 'text': ..., 'subject': 'history'}, ...]
Delete result: {'delete_count': 3}
基本操作说明
| 操作 | 方法 | 说明 |
|---|---|---|
| 创建集合 | create_collection | 定义向量维度 |
| 插入数据 | insert | 批量插入向量和元数据 |
| 相似性搜索 | search | 向量最近邻搜索 |
| 条件查询 | query | 类似SQL的条件筛选 |
| 删除数据 | delete | 根据条件删除记录 |
混合向量存储
本节介绍如何创建一个同时存储密集向量和稀疏向量的 Collection。
from typing import List
from langchain_core.documents import Document
from pymilvus import IndexType, MilvusClient
from pymilvus.client.types import MetricType
from langchain_milvus import Milvus, BM25BuiltInFunction
from document.markdown_parser import MarkdownParser
from llm_models.embeddings_model import bge_embedding
from utils.env_utils import MILVUS_URI, COLLECTION_NAME
class MilvusVectorSave:
"""把新的 document 数据插入到数据库中"""
def __init__(self):
"""collection 的索引定义"""
self.vector_store_saved: Milvus = None
self.index_params = [
{
# 密集向量字段,下面的配置适合大部分企业的配置
"field_name": "dense",
"index_name": "dense_vector_index",
"index_type": IndexType.HNSW, # 一种基于图的近似最近邻算法
"metric_type": MetricType.IP, # 相似度的度量方式,L2或IP
"params": {
"M": 16, # 近邻节点数,范围 4-64
"efConstruction": 64 # 搜索范围,范围 50-200
}
},
{
"field_name": "sparse",
"index_name": "sparse_inverted_index",
"index_type": "SPARSE_INVERTED_INDEX",
"metric_type": "BM25",
"params": {
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.6,
"bm25_b": 0.75,
},
}
]
def create_collection(self, is_first=True):
"""创建一个 collection,milvus+langchain"""
client = MilvusClient(uri=MILVUS_URI)
# 判断是否存在 collection
if is_first:
if COLLECTION_NAME in client.list_collections():
# 先释放,再删除索引,再删除 collection
client.release_collection(collection_name=COLLECTION_NAME)
client.drop_index(collection_name=COLLECTION_NAME, index_name='dense_vector_index')
client.drop_index(collection_name=COLLECTION_NAME, index_name='sparse_inverted_index')
client.drop_collection(collection_name=COLLECTION_NAME)
# 创建向量存储
self.vector_store_saved = Milvus(
embedding_function=bge_embedding,
collection_name=COLLECTION_NAME,
builtin_function=BM25BuiltInFunction(), # BM25稀疏向量函数
vector_field=['dense', 'sparse'],
index_params=self.index_params,
consistency_level='Strong', # 一致性级别
auto_id=True,
connection_args={"uri": MILVUS_URI},
)
def add_documents(self, datas: List[Document]):
"""把新的 document 保存到 Milvus 中"""
self.vector_store_saved.add_documents(datas)
一致性级别
| 级别 | 描述 | 适用场景 |
|---|---|---|
"Strong" | 写入后立即可读,最高一致性 | 金融交易、实时计费 |
"Session" | 当前会话内一致(默认) | 大多数读写场景 |
"Bounded" | 允许短暂延迟 | 高吞吐场景 |
"Eventually" | 最终一致,延迟最低 | 日志分析、离线计算 |
注意:BM25BuiltInFunction 是 Milvus Function 的轻��量级封装,用于自动将文本转换为稀疏向量。该功能在 Milvus Standalone 和 Distributed 可用,但在 Milvus Lite 中不可用。
使用示例
if __name__ == '__main__':
file_path = r'C:\Users\21129\PycharmProjects\RAG_PROJECT\data\md\tech_report_0tfhhamx.md'
parser = MarkdownParser()
docs = parser.parse_markdown_to_documents(file_path)
milvus_vector_save = MilvusVectorSave()
milvus_vector_save.create_collection(is_first=True)
milvus_vector_save.add_documents(docs)
client = milvus_vector_save.vector_store_saved.client
# 查看表结构
desc_collection = client.describe_collection(collection_name=COLLECTION_NAME)
print('表结构是:', desc_collection)
# 查看所有索引
res = client.list_indexes(collection_name=COLLECTION_NAME)
print('表中的所有索引:', res)
# 查看每个索引的详细信息
if res:
for index_name in res:
desc_index = client.describe_index(
collection_name=COLLECTION_NAME,
index_name=index_name
)
print(desc_index)
# 条件�查询
result = client.query(
collection_name=COLLECTION_NAME,
filter='category=="Title"',
output_fields=['text', 'category', 'filename']
)
print('查询结果', result)
表结构说明
创建后的 Collection 包含以下字段:
| 字段名 | 类型 | 说明 |
|---|---|---|
| pk | INT64 | 主键(自动生成) |
| text | VARCHAR | 原始文本 |
| dense | FLOAT_VECTOR | 密集向量(由BGE嵌入生成) |
| sparse | SPARSE_FLOAT_VECTOR | 稀疏向量(由BM25函数生成) |
| source | VARCHAR | 来源 |
| category | VARCHAR | 分类 |
| filename | VARCHAR | 文件名 |
| title | VARCHAR | 标题 |
索引说明
| 索引类型 | 字段 | 说明 |
|---|---|---|
| HNSW | dense | 密集向量索引 |
| SPARSE_INVERTED_INDEX | sparse | 稀疏向量索引 |
HNSW 参数:
M:近邻节点数,值�越大精度越高(推荐 4-64)efConstruction:构建索引时的搜索范围(推荐 50-200)
BM25 参数:
bm25_k1:词频饱和度参数(推荐 1.2-2.0)bm25_b:文档长度归一化参数(推荐 0.75)
附录:Markdown 文档解析
在将文档存入 Milvus 之前,通常需要对 Markdown 文件进行解析和切分。以下是完整的解析方法:
from typing import List # 类型提示,List 表示文档列表
from langchain_experimental.text_splitter import SemanticChunker # 语�义切分器
from langchain_openai import OpenAIEmbeddings # OpenAI嵌入模型
from langchain_community.document_loaders import UnstructuredMarkdownLoader # Markdown加载器
from langchain_core.documents import Document # LangChain文档对象
class MarkdownParser:
"""
专门负责markdown文件的解析和切片
处理流程:解析 -> 合并标题 -> 语义切分
"""
def __init__(self):
# 初始化语义切分器,使用OpenAI嵌入模型
# breakpoint_threshold_type="percentile" 表示按百分比自动确�定断点
self.text_splitter = SemanticChunker(
OpenAIEmbeddings(),
breakpoint_threshold_type="percentile" # 基于语义相似度百分比切分
)
def parse_markdown_to_documents(self, md_file: str) -> List[Document]:
"""
主流程:解析Markdown文件并返回切分后的文档列表
步骤:1.解析Markdown 2.合并标题与正文 3.语义切分长文本
"""
# 步骤1:解析Markdown文件为Document列表
documents = self.parse_markdown(md_file)
# 步骤2:将标题与对应的正文内容合并
merged_documents = self.merge_title_content(documents)
# 步骤3:对超过6000字符的长文本进行语义切分
chunk_documents = self.text_chunker(merged_documents)
return chunk_documents
def parse_markdown(self, md_file: str) -> List[Document]:
"""
使用UnstructuredMarkdownLoader解析Markdown文件
mode='elements': 将文档拆分为多个独立元素(标题、正文、表格等)
strategy='fast': 快速解析模式
"""
loader = UnstructuredMarkdownLoader(
file_path=md_file, # Markdown文件路径
mode='elements', # 拆分为独立元素
strategy='fast' # 快速解析
)
# lazy_load() 懒加载,返回迭代器,转为列表
return list(loader.lazy_load())
def merge_title_content(self, datas: List[Document]) -> List[Document]:
"""
合并标题与正文
例如:将 "## 第一节" 和下面的正文内容合并为一个Document
"""
merged_data = [] # 存储合并后的文档
parent_dict = {} # 字典,key为element_id,value为父Document
for document in datas:
# 获取文档的元数据
metadata = document.metadata
# 获取关键字段
parent_id = metadata.get('parent_id', None) # 父元素ID
category = metadata.get('category', None) # 元素类别(Title/NarrativeText等)
element_id = metadata.get('element_id', None) # 当前元素ID
# 情况1:独立的正文内容(没有父元素)直接添加
if category == 'NarrativeText' and parent_id is None:
merged_data.append(document)
# 情况2:标题元素,保存到parent_dict
if category == 'Title':
# 将标题内容保存到metadata中
document.metadata['title'] = document.page_content
# 如果有父元素,将父元素的内容拼接到标题前
# 格式:父内容 -> 标题内容
if parent_id in parent_dict:
document.page_content = parent_dict[parent_id].page_content + ' -> ' + document.page_content
# 保存到字典,key为element_id
parent_dict[element_id] = document
# 情况3:有父元素的非标题内容,拼接到父元素中
if category != 'Title' and parent_id:
# 将内容追加到父元素的page_content
parent_dict[parent_id].page_content = parent_dict[parent_id].page_content + ' ' + document.page_content
# 修改父元素的category为content
parent_dict[parent_id].metadata['category'] = 'content'
# 将parent_dict中剩余的文档也加入结果
if parent_dict is not None:
merged_data.extend(parent_dict.values())
return merged_data
def text_chunker(self, datas: List[Document]) -> List[Document]:
"""
语义切分长文本
对于超过6000字符的文档,使用SemanticChunker进行语义切分
"""
new_docs = [] # 存储��切分后的文档
for d in datas:
# 如果文档长度超过6000字符,进行语义切分
if len(d.page_content) > 6000:
# 使用SemanticChunker切分,返回多个Document
new_docs.extend(self.text_splitter.split_documents([d]))
else:
# 长度适中,直接保留
new_docs.append(d)
return new_docs
使用�示例:
# 1. 创建解析器
parser = MarkdownParser()
# 2. 解析Markdown文件,得到Document列表
docs = parser.parse_markdown_to_documents('your_file.md')
# 3. 将文档存入Milvus
milvus_vector_save.add_documents(docs)
附录:MilvusVectorSave 工具类(优化版)
以下是优化后的完整代码,索引配置现在会正确生效:
from typing import List # 导入列表类型提示
from langchain_core.documents import Document # 导入LangChain文档对象
from pymilvus import IndexType, MilvusClient, Function # 导入Milvus相关类
from pymilvus.client.types import MetricType, FunctionType, DataType # 导入Milvus类型定义
from langchain_milvus import Milvus, BM25BuiltInFunction # 导入LangChain Milvus封装
from document.markdown_parser import MarkdownParser # Markdown解析器
from llm_models.embeddings_model import bge_embedding # BGE嵌入模型
from utils.env_utils import MILVUS_URI, COLLECTION_NAME # 环境变量配置
class MilvusVectorSave:
"""
Milvus向量存储工具类
功能:创建Collection、存储Document、查询
特点:支持混合存储(密集向量BGE + 稀疏向量BM25)
"""
def __init__(self):
"""初始化向量存储对象"""
self.vector_store_saved: Milvus = None # LangChain Milvus向量存储对象
def create_collection(self):
"""
创建一个新的Collection
包含完整的索引配置,索引会在创建时生效
"""
client = MilvusClient(uri=MILVUS_URI) # 创建Milvus客户端
# 1. 创建Schema(表结构)
schema = client.create_schema()
schema.add_field(field_name='id', datatype=DataType.INT64, is_primary=True, auto_id=True) # 主键
# 文本字段:启用jieba中文分词
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
enable_analyzer=True, # 启用分析器
analyzer_params={'tokenizer': 'jieba', 'filter': ['cnalphanumonly']}, # jieba分词配置
max_length=6000
)
schema.add_field(field_name='category', datatype=DataType.VARCHAR, max_length=1000) # 分类
schema.add_field(field_name='source', datatype=DataType.VARCHAR, max_length=1000) # 来源
schema.add_field(field_name='category_depth', datatype=DataType.INT64) # ��分类深度
schema.add_field(field_name='filename', datatype=DataType.VARCHAR, max_length=1000) # 文件名
schema.add_field(field_name='filetype', datatype=DataType.VARCHAR, max_length=1000) # 文件类型
schema.add_field(field_name='title', datatype=DataType.VARCHAR, max_length=1000) # 标题
schema.add_field(field_name='sparse', datatype=DataType.SPARSE_FLOAT_VECTOR) # 稀疏向量字段
schema.add_field(field_name='dense', datatype=DataType.FLOAT_VECTOR, dim=512) # 密集向量字段
# 2. 定义BM25函数:将文本转换为稀疏向量
bm25_function = Function(
name='text_bm25_emb', # Function名称
input_field_names=['text'], # 输入字段:原始文本
output_field_names=['sparse'], # 输出字段:稀疏向量
function_type=FunctionType.BM25
)
schema.add_function(bm25_function)
# 3. 配置索引参数(关键!)
index_params = client.prepare_index_params()
# 稀疏向量索引(BM25)
index_params.add_index(
field_name="sparse",
index_name="sparse_inverted_index",
index_type="SPARSE_INVERTED_INDEX", # 倒排索引
metric_type="BM25",
params={
"inverted_index_algo": "DAAT_MAXSCORE", # 评分算法
"bm25_k1": 1.6, # 词频饱和度参数,范围:[1.2 ~ 2.0]
"bm25_b": 0.75 # 文档长度归一化参数
},
)
# 密集向量索引(HNSW)
index_params.add_index(
field_name='dense',
index_name='dense_inverted_index',
index_type=IndexType.HNSW, # HNSW近似最近邻算法
metric_type=MetricType.IP, # 内积相似度
params={
'M': 16, # 邻接节点数
'efConstruction': 64 # 搜索范围
}
)
collection_name = COLLECTION_NAME
# 4. 如果Collection已存在,则删除重建
if collection_name in client.list_collections():
client.release_collection(collection_name=collection_name) # 释放Collection
client.drop_index(collection_name=collection_name, index_name='sparse_inverted_index') # 删除稀疏索引
client.drop_collection(collection_name=collection_name) # 删除Collection
# 5. 创建Collection,传入索引参数
client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params, # 索引在这里生效!
)
print(f"Collection '{collection_name}' 创建成功")
def create_connection(self):
"""
创建与Milvus的连接(使用LangChain)
注意:Collection必须先创建好,这里只是建立连接
"""
self.vector_store_saved = Milvus(
embedding_function=bge_embedding, # 密集向量生成函数(BGE模型)
collection_name=COLLECTION_NAME,
builtin_function=BM25BuiltInFunction(), # 稀疏向量生成函数(BM25)
vector_field=['dense', 'sparse'], # 向量字段
consistency_level='Strong', # 强一致性
auto_id=True, # 自动生成ID
connection_args={"uri": MILVUS_URI}
)
def add_documents(self, datas: List[Document]):
"""
添加文档到Milvus
参数:
datas: Document对象列表
"""
self.vector_store_saved.add_documents(datas)
print(f"成功插入 {len(datas)} 条数据")
# 使用示例
if __name__ == '__main__':
# 1. 解析Markdown文件
file_path = r'C:\Users\21129\PycharmProjects\RAG_PROJECT\data\md\tech_report_0tfhhamx.md'
parser = MarkdownParser()
docs = parser.parse_markdown_to_documents(file_path)
# 2. 创建Milvus工具类
milvus_vector_save = MilvusVectorSave()
# 3. 创建Collection(包含索引配置)
milvus_vector_save.create_collection()
# 4. 创建连接
milvus_vector_save.create_connection()
# 5. 插入数据
milvus_vector_save.add_documents(docs)
# 6. 获取底层客户端
client = milvus_vector_save.vector_store_saved.client
# 7. 查看表结构
desc_collection = client.describe_collection(collection_name=COLLECTION_NAME)
print('表结构是:', desc_collection)
# 8. 查看所有索引
res = client.list_indexes(collection_name=COLLECTION_NAME)
print('表中的所有索引:', res)
if res:
for index_name in res:
# 查看每个索引的详细信息
desc_index = client.describe_index(
collection_name=COLLECTION_NAME,
index_name=index_name
)
print(desc_index)
# 9. 条件查询
result = client.query(
collection_name=COLLECTION_NAME,
filter='category=="Title"',
output_fields=['text', 'category', 'filename']
)
print('查询结果', result)
保存截图如下
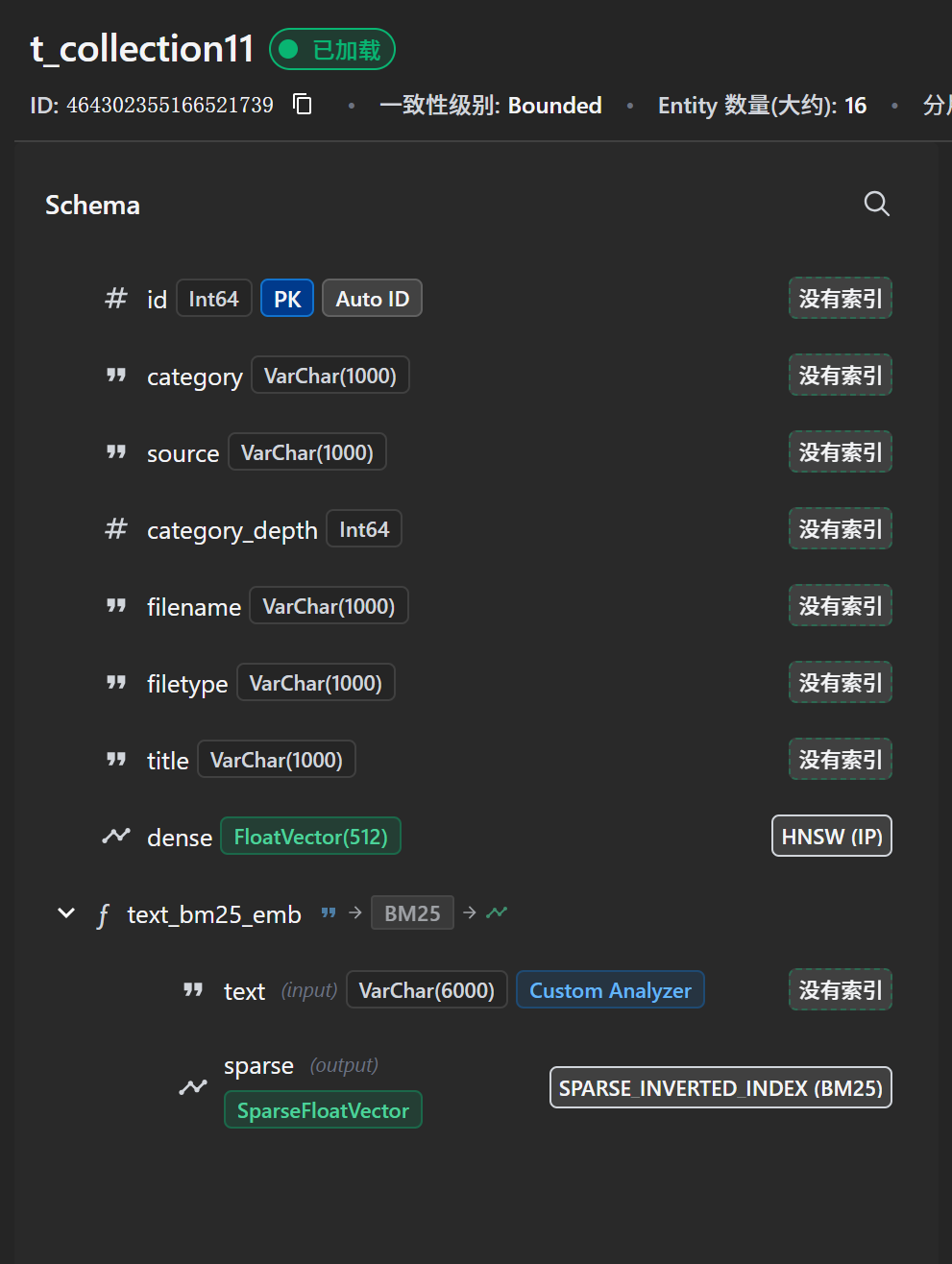
关键改进说明
| 改进点 | 说明 |
|---|---|
| 索引显式创建 | 在 create_collection() 中通过 index_params 显式创建索引 |
| jieba 分词 | 使用 analyzer_params={'tokenizer': 'jieba'} 启用中文分词 |
| 字段扩展 | 新增 source、category_depth、filetype 等字段 |
| 向量维度 | 密集向量使用 512 维(BGE-small),BGE-large 需用 1024 |
| 索引分离 | 稀疏索引和密集索引分别创建,清晰管理 |
索引生效原理
create_collection()
↓
client.create_collection(..., index_params=index_params)
↓
Milvus 服务器端创建索引
↓
插入数据时自动使用索引进行加速搜索
重要:索引必须在 create_collection() 时通过 index_params 参数传递给 Milvus,否则搜索时无法使用索引加速。